微软最近提出了一个有趣的方法,即使用合成教科书来教授模型,而不是通常使用的大规模数据集。
论文原文:https://arxiv.org/abs/2306.11644
这篇论文介绍了一个名为Phi-1的模型,它完全是在一本定制的教科书上进行训练的。研究人员发现,对于某些任务,这种方法和使用大量数据进行训练的规模更大的模型一样有效。
标题”Textbooks Are All You Need”巧妙地引用了人工智能领域中众所周知的概念“Attention is All You Need”。但在这里,他们颠覆了这个想法——与其专注于模型体系结构本身,不如展示像在教科书中找到的高质量策划训练数据的价值。

论文的关键思路:一个经过深思熟虑、设计良好的数据集对于教授人工智能模型可以和庞大而缺乏焦点的数据堆一样有用。因此,研究人员制作了一本合成教科书,精心为模型提供所需的知识。
这基于教科书的方法是一个引人入胜的新方向,可以有效地训练人工智能模型以在特定任务上表现卓越。它强调了对培训数据的策划和质量的重要性,而不仅仅是数据规模的强大。
主要观点
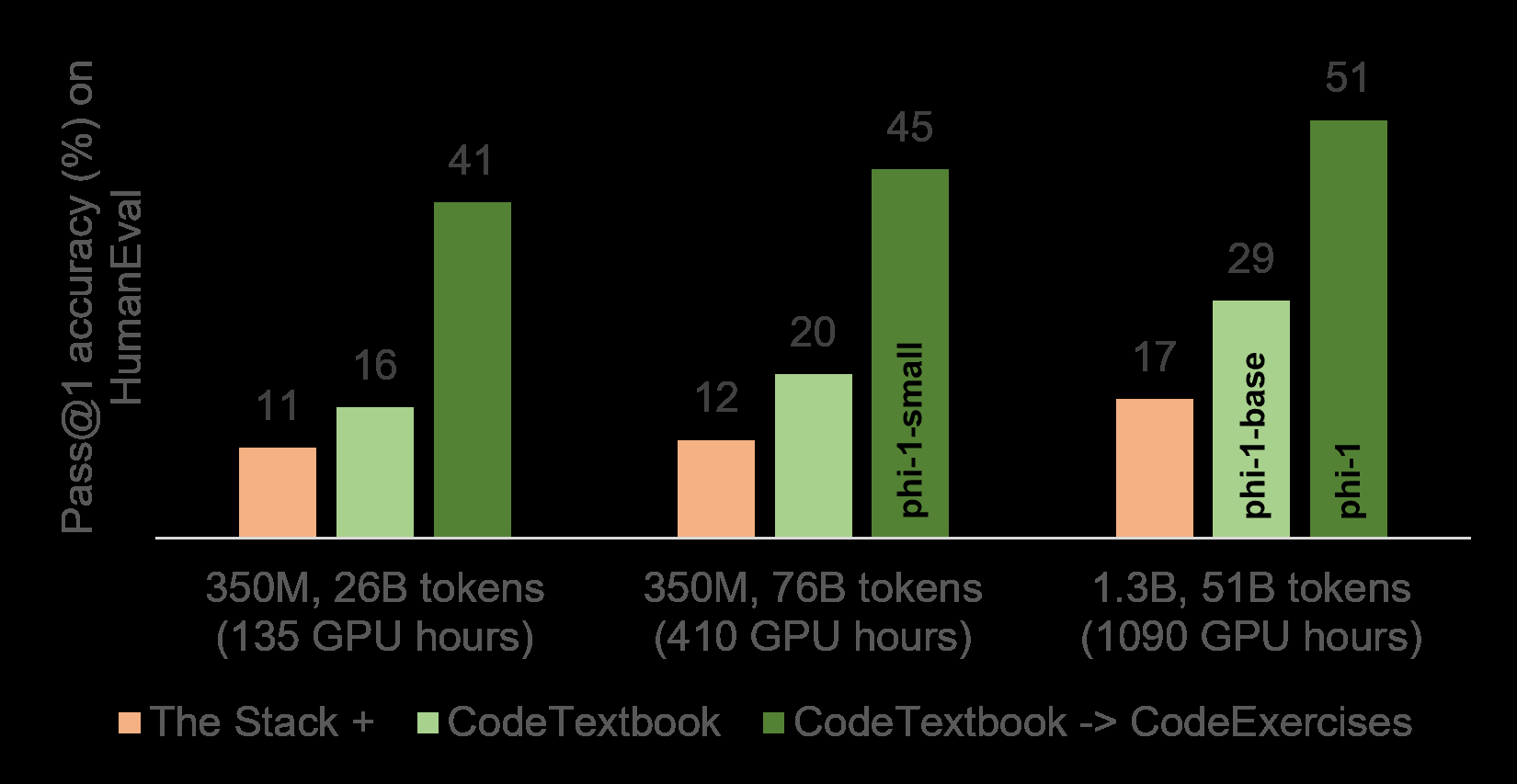
- 尽管Phi-1模型比GPT-3等模型要小得多,但在Python编码任务中表现出色。这表明在人工智能模型方面,规模并非一切。
- 研究人员使用合成教科书进行训练,强调了高质量、经过精心策划的数据的重要性。这种方法可能会改变我们对于培训人工智能模型的看法。
- 通过使用合成的练习和解决方案对Phi-1模型进行微调,其性能显著提高,表明有针对性的微调可以增强模型在特定任务之外的能力。
讨论
Phi-1模型具有13亿个参数,相对于拥有1750亿参数的GPT-3等模型来说,规模较小。尽管如此,Phi-1在Python编码任务中表现出色,突显了培训数据的质量对于模型的重要性,甚至可能比模型规模更为关键。
研究人员使用合成教科书来训练Phi-1模型,该教科书是使用GPT-3.5生成的,包含了Python文本和练习。使用合成教科书强调了在培训人工智能模型时高质量、精心策划数据的重要性。这一方法有可能将人工智能培训的焦点从创建更大模型转向策划更好的培训数据。
有趣的是,通过使用合成的练习和解决方案对Phi-1模型进行微调,其性能显著提高。这种改进并不仅限于其特定训练任务。例如,模型使用外部库(如pygame)的能力得到改善,尽管这些库并未包含在训练数据中。这表明微调可以增强模型在特定训练任务之外的能力。