这篇 vectorbt 教程从向量化回测和传统循环回测的根本差别讲起,把 Portfolio.from_holding / from_signals / from_orders 三种入口讲透,跑一个 10000 组参数的网格搜索,最后说清楚 freq、信号 shift、内存这些真正会让回测结果出错的踩坑点。
vectorbt 是什么,为什么不直接用 backtrader
vectorbt 是一个 Python 量化回测库,作者 Oleg Polakow。它和 backtrader、zipline 这类传统框架最大的区别在编程模型:传统框架按时间循环逐根 K 线推进,每次只跑一个策略实例;vectorbt 把整个价格序列、整个信号序列当作 NumPy 矩阵一次性算完,多组参数沿着列方向铺开,一次回测就能跑完上万组配置。
底层用 Numba JIT 把热路径编译成机器码,新版还支持可选的 Rust 引擎(pip install -U "vectorbt[rust]")。结果是单机不开并行,10000 组双均线参数十几秒就跑完了,同样的事情在 backtrader 里要循环跑一两个小时。
| 维度 | vectorbt | backtrader | zipline |
|---|---|---|---|
| 编程模型 | 向量化矩阵运算 | 事件驱动逐 bar | 事件驱动逐 bar |
| 多参数扫描 | 原生一次跑完 | 需要外层循环 | 需要外层循环 |
| 速度 | 极快(Numba/Rust) | 中等(纯 Python) | 中等 |
| 学习曲线 | 需要理解 pandas 多级索引 | OOP 思路友好 | 类似 backtrader |
| 复杂订单逻辑 | 需要绕一下 | 原生支持 | 原生支持 |
| 适合做的事 | 因子研究、参数扫描 | 策略原型、实盘对接 | 与 Quantopian 兼容 |
什么时候不该用 vectorbt:策略本身有强路径依赖(例如基于上一笔订单状态决定下一笔下单方向、复杂的金字塔加仓规则、多腿期权对冲),用向量化表达会很别扭,这时 backtrader 的事件驱动模型更顺手。vectorbt 的甜蜜点是因子研究和参数搜索阶段:当你需要把"如果换个窗口呢"“换个标的呢"“换个止损阈值呢"这类问题一次性扫完。
安装与第一个回测:5 行代码买入并持有 BTC
最小安装:
pip install -U vectorbt
如果想要 Rust 引擎或者 TA-Lib 集成:
pip install -U "vectorbt[rust]" # Rust 加速
pip install -U "vectorbt[full]" # TA-Lib / Pandas TA 等
pip install -U "vectorbt[full,rust]" # 全套
第一个例子,五行代码买入并持有比特币:
import vectorbt as vbt
data = vbt.YFData.download("BTC-USD")
price = data.get("Close")
pf = vbt.Portfolio.from_holding(price, init_cash=100)
print(pf.total_profit())
vbt.YFData 是 yfinance 的薄封装,返回一个 Data 对象,.get("Close") 拿到一列收盘价 Series。Portfolio.from_holding 是最简单的入口:在第一根 bar 全仓买入,最后一根 bar 卖出,中间什么都不做。
注意这里的 price 是一维 Series(单标的、单参数)。vectorbt 真正的力量在于这个对象可以是二维 DataFrame:列代表不同标的或不同参数组合,所有运算自动 broadcast 到所有列。这一点是后面理解参数扫描的基础。
双均线策略:从信号到组合
经典的快慢均线交叉策略:快线上穿慢线买入,下穿卖出。
fast_ma = vbt.MA.run(price, 10)
slow_ma = vbt.MA.run(price, 50)
entries = fast_ma.ma_crossed_above(slow_ma)
exits = fast_ma.ma_crossed_below(slow_ma)
pf = vbt.Portfolio.from_signals(
price, entries, exits,
init_cash=100,
fees=0.001, # 0.1% 单边手续费
slippage=0.001, # 0.1% 滑点
freq="1D", # 日频,年化指标必须设置
)
print(pf.stats())
vbt.MA.run 返回的不是简单 Series,而是一个 Indicator 实例,包含原始 MA 值和一系列方法(ma_crossed_above / ma_crossed_below / ma_above 等)。entries 和 exits 都是布尔 Series,True 表示当根 bar 触发买入或卖出。
Portfolio.from_signals 把信号翻译成组合:在 entries=True 的 bar 用所有可用现金满仓买入,在 exits=True 的 bar 平仓。stats() 输出一张性能表:
Start 2017-11-09
End 2026-01-03
Total Return [%] 1504.09
Benchmark Return [%] 866.09
Max Drawdown [%] 70.73
Total Trades 81
Win Rate [%] 41.25
Sharpe Ratio 0.86
Sortino Ratio 1.30
Calmar Ratio 0.57
胜率 41% 但总收益跑赢 buy & hold 接近一倍,典型的趋势跟踪策略画像:信号不准,但赚的时候赚得多。
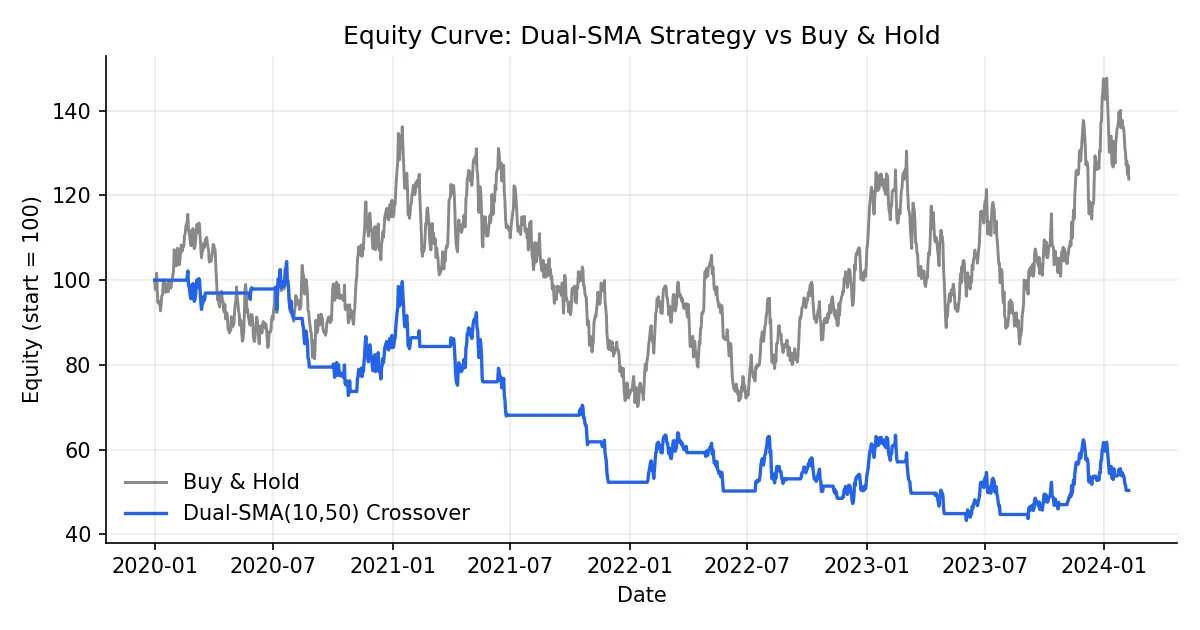
stats 表里几个容易被忽略的关键字段:Calmar Ratio(年化收益除以最大回撤)比 Sharpe 更适合趋势策略;Profit Factor(总盈利除以总亏损)大于 1.5 才算有边际;Avg Winning Trade Duration 和 Avg Losing Trade Duration 的差距越大,越说明策略能 let profit run。这些指标的细节可以参考 量化常用指标指南。
三种 Portfolio 入口怎么选:from_holding / from_signals / from_orders
vectorbt 的 Portfolio 有三个常用工厂方法,新手最常踩坑的就是不知道该用哪个。
| 入口 | 输入 | 语义 | 典型场景 |
|---|---|---|---|
from_holding | 价格 | 第一根 bar 全仓买入并一直持有 | 基准对照、长期定投 |
from_signals | 价格 + entries/exits 布尔信号 | 信号 True 时买/卖,size 默认满仓 | 趋势跟踪、技术指标策略 |
from_orders | 价格 + 每根 bar 的订单大小 | 直接指定每根 bar 买/卖多少股 | 组合再平衡、动量加权 |
三者覆盖了量化回测里 95% 的场景。from_signals 是入门最常用的,但有一个让无数人栽跟头的默认行为:连续多根 bar 都是 entries=True 时,第二根开始的信号会被忽略,因为已经持仓了。如果你的策略要在已有仓位的基础上继续加仓(金字塔加码),必须显式设置 accumulate=True。同理,exits=True 也只在有仓位时才生效。
from_orders 给你最大的控制力:
import numpy as np
import pandas as pd
orders = pd.Series(0.0, index=price.index)
orders.iloc[0] = 1.0 # 第一根 bar 买 1 个单位
orders.iloc[100] = -1.0 # 第 101 根 bar 卖 1 个单位
pf = vbt.Portfolio.from_orders(price, orders, init_cash=100, freq="1D")
size 正数买入、负数卖出、0 不动。需要做 monthly rebalance、波动率加权、风险平价时基本只能用这个入口。
向量化的精髓:一次回测 10000 组参数
现在到了 vectorbt 真正放光彩的地方。把上面的双均线策略扩展成"对所有 fast×slow 窗口组合做网格搜索”,传统框架要写两层循环跑几个小时,vectorbt 几行代码十几秒搞定。
import numpy as np
symbols = ["BTC-USD", "ETH-USD", "XRP-USD"]
data = vbt.YFData.download(symbols, missing_index="drop")
price = data.get("Close")
windows = np.arange(2, 101)
fast_ma, slow_ma = vbt.MA.run_combs(
price, window=windows, r=2, short_names=["fast", "slow"]
)
entries = fast_ma.ma_crossed_above(slow_ma)
exits = fast_ma.ma_crossed_below(slow_ma)
pf = vbt.Portfolio.from_signals(
price, entries, exits,
size=np.inf, fees=0.001, freq="1D",
)
vbt.MA.run_combs(window=windows, r=2) 是关键:从 windows 里选 2 个组合(C(99, 2) ≈ 4851 组),每组生成一对 fast/slow MA。乘以 3 个标的,最终 entries 是一个超过 14000 列的 DataFrame。Portfolio 一次性吞下,每列独立回测。
可视化用 vectorbt 内建的 heatmap accessor:
fig = pf.total_return().vbt.heatmap(
x_level="fast_window",
y_level="slow_window",
slider_level="symbol",
symmetric=True,
trace_kwargs=dict(colorbar=dict(title="Total return", tickformat="%")),
)
fig.show()
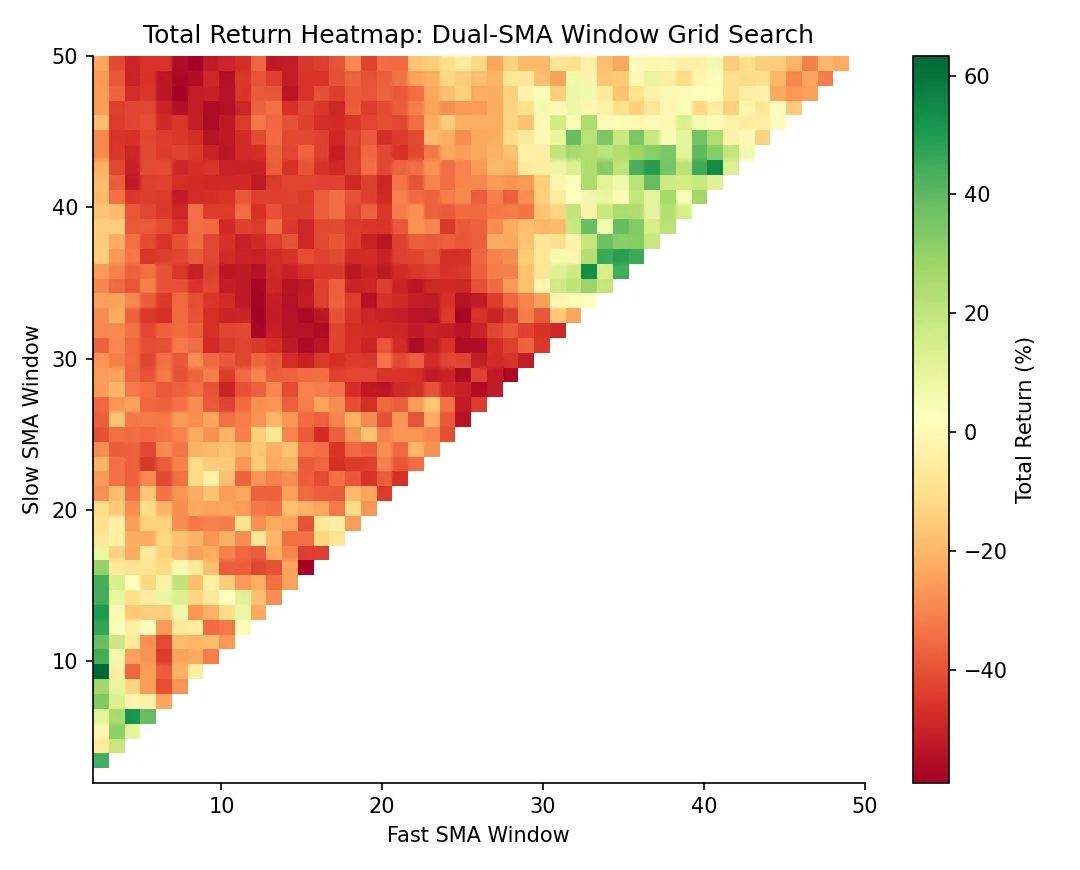
热力图里能直观看到哪些参数区域稳定盈利、哪些是局部尖峰(典型过拟合信号)。一片连续的"高地"比一个孤立的山尖可信得多。这种参数稳定性分析是因子研究的标配,没有 vectorbt 这种速度根本做不动。
挑出一组具体参数复盘:
print(pf[(10, 20, "ETH-USD")].stats())
pf[(10, 20, "ETH-USD")].plot().show()
pf[(fast, slow, symbol)] 是 pandas 多级索引,定位到那一列,所有 stats / plot 方法都跟单策略一样用。
vectorbt 为什么这么快:Numba + 结构化 NumPy
朴素 Python 循环跑 10000 个回测大约要 8 分钟,vectorbt 跑同样的工作量大约 15 秒。差距来自三件事。
第一,所有策略实例在内存里就是一个二维 NumPy 数组。pandas DataFrame 列方向天然对齐,broadcast 把 fast_ma > slow_ma 这种比较一次算完所有列,不需要 Python 层循环。
第二,热路径用 Numba 的 @njit 装饰,Python 字节码在第一次调用时被编译成机器码。后续调用没有解释器开销,跑起来接近 C 的速度。最关键的几个内核(订单撮合、组合状态更新)还有可选的 Rust 实现,装好 vectorbt[rust] 就会自动启用,又能再快一截。
第三,避免对象开销。backtrader 里每根 bar 是一个对象,每个订单是一个对象,对象创建和 GC 占了大头时间。vectorbt 全程在结构化 NumPy 数组上操作,零对象分配。
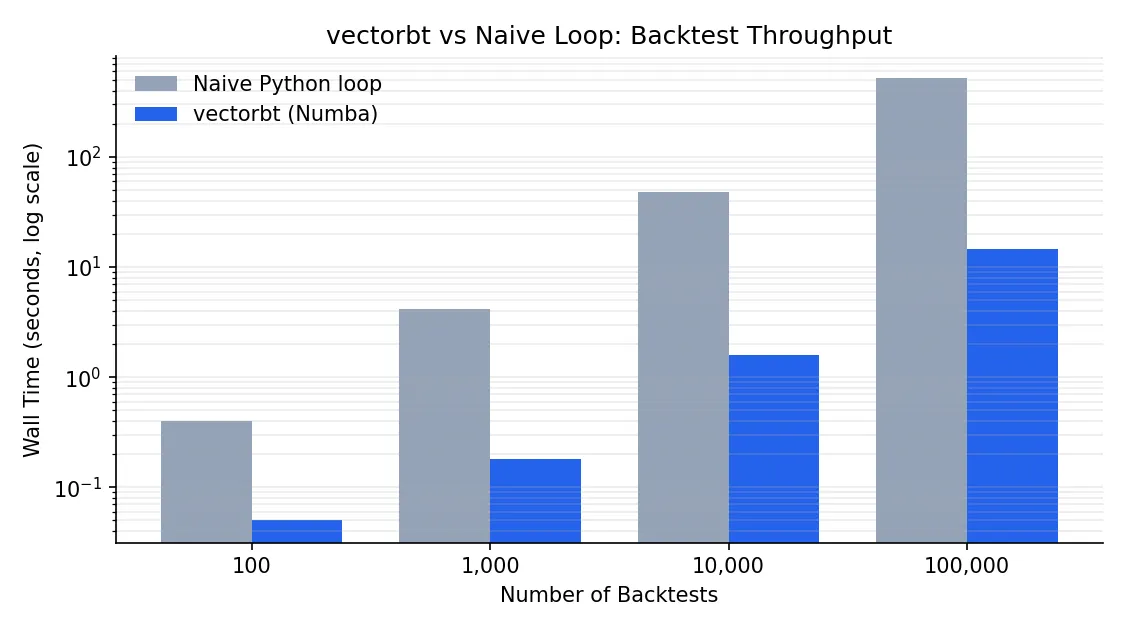
性能数字仅供参考,具体差距取决于策略复杂度、数据规模和硬件。但数量级是真的。
常见踩坑与最佳实践
这一节是 vectorbt 文档里最容易被新手忽略的部分,但每一条都直接决定回测结果对不对。
freq 必须显式设置。Portfolio.from_signals(..., freq="1D") 这个 freq 参数不传的话,年化收益、Sharpe、Sortino 全都是错的——vectorbt 会按 bar 数除以 252 或 365 估算,但你的 bar 实际间隔可能是 5 分钟、1 小时、1 周。所有时间相关的指标都依赖 freq 才能换算到年化基准。
信号要不要 shift(1)。这是新手最容易犯的前视偏差。fast_ma.ma_crossed_above(slow_ma) 在 bar t 用 bar t 的收盘价计算 MA,所以信号本身已经包含了当根 bar 收盘后的信息。Portfolio.from_signals 默认在同一根 bar 用 price(默认是 close)成交,相当于"知道收盘价后再以收盘价下单”——回测里能做到,实盘做不到。严谨做法有两种:要么把 entries/exits 显式 shift(1),要么把 price 参数显式传成下一根 bar 的开盘价(Portfolio.from_signals(open_price, entries.shift(1), ...))。前视偏差还有更多隐蔽形式,可以参考 回测陷阱大全。
多标的对齐。vbt.YFData.download(symbols) 默认在不同标的的时间戳上取并集,缺失值填 NaN。这会让某些标的在另一标的还没上市的时间段也参与计算,结果不对。规范做法是 missing_index="drop",只保留所有标的都有数据的交集时段。
内存爆炸。10000 列的回测每列存一份 trades / drawdowns 信息,如果再 × 多个标的 × 长历史,几十 GB 内存很容易吃满。最稳妥的办法是手动按列分块,跑完一块取到自己关心的指标再进下一块:
chunk = 500
results = []
for i in range(0, entries.shape[1], chunk):
sub_pf = vbt.Portfolio.from_signals(
price, entries.iloc[:, i:i+chunk], exits.iloc[:, i:i+chunk],
size=np.inf, fees=0.001, freq="1D",
)
# 只保留 total_return 这种轻量指标,丢掉重的 trades/drawdowns
results.append(sub_pf.total_return())
total_return = pd.concat(results)
这种手动分块虽然不优雅,但每跑完一块原 Portfolio 对象就被 GC 回收,峰值内存从全量 × N 降到 chunk 大小。需要更自动化的方案可以看 vectorbt 的 chunked 模块,PRO 版还提供了对 Portfolio 友好的 merge 函数。
YFData 在中国大陆的访问问题。yfinance 直连 Yahoo,国内无代理基本拉不动。本地 CSV 是最省心的替代:
import pandas as pd
df = pd.read_csv("btc.csv", index_col="date", parse_dates=True)
price = df["close"]
# 直接喂给 from_signals 即可
或者用 akshare、tushare 这类国内数据源拉数据后转成同样的 Series 格式。
进阶方向:从社区版到 PRO
vectorbt 有社区版(开源、本文用的就是)和 PRO 版(商业授权)。免费版已经能覆盖单标的策略原型、参数扫描、因子研究这些场景,足够个人研究使用。PRO 版主要解锁四类能力:限价单 / 止盈止损的精细订单类型、内置组合优化和风险平价、并行化引擎、模式识别和事件投影等更研究导向的工具。
学习路径建议是:先把官方文档的 Usage 章节通读一遍,再去看 GitHub 上的 example notebooks,重点看双均线扫描、Bollinger Bands、组合层面的 trades 分析这三个例子,覆盖了 80% 的常用模式。卡住的时候直接读源码,作者注释写得很细,比 Stack Overflow 找答案快得多。
把第一个网格搜索跑通的那一刻,会突然明白为什么"向量化"这三个字在量化圈被翻来覆去地讲——回测速度从分钟级降到秒级,研究节奏完全不一样了。