AlphaAgent 那篇 解决的是"LLM 挖出来的因子太像,加速 alpha decay",用的是因子层面的正则化。QuantaAlpha(arXiv 2602.07085)的视角抬高了一层:与其在单次生成上加约束,不如把"假设→因子→回测"的整个 pipeline 看作一条 trajectory,然后在 trajectory 之间做变异和交叉。在 CSI 300 上用 GPT-5.2 拿到 IC 0.0472、ARR 4.68%、MDD 11.8%,跨市场零样本迁移到 CSI 500 和 S&P 500 还分别留下 40.28% 和 19.1% 的累计超额收益。
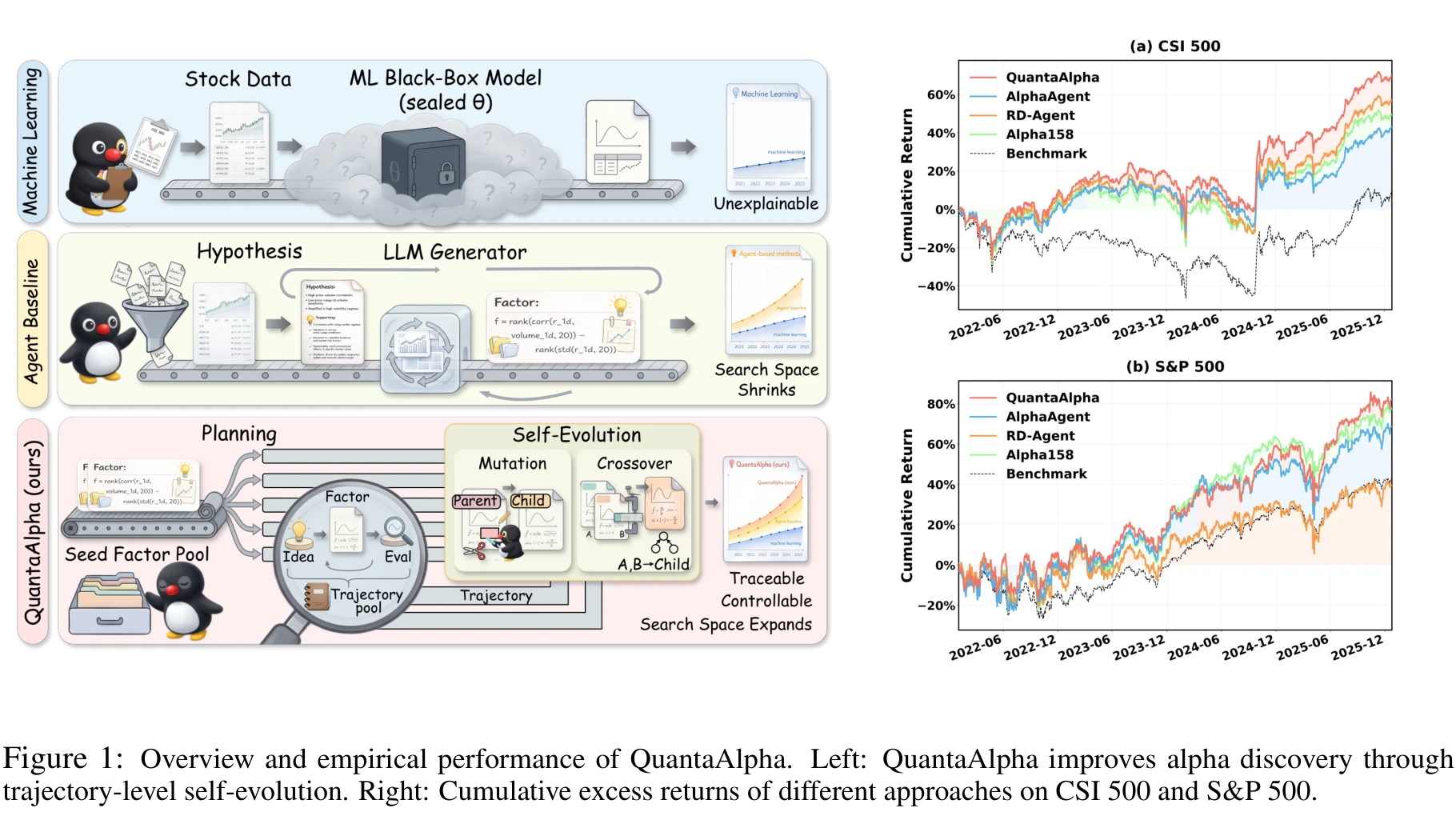
LLM 因子挖掘的三个老毛病
把 LLM 当成因子研究员来用,过去两年的主流路线大致是:先让模型生成市场假设,再翻译成因子表达式,回测打分,根据反馈再生成。AlphaAgent、RD-Agent 都是这个套路。论文把这条路线现存的麻烦总结成三条:
可控性脆弱。 迭代完全靠回测分数当指挥棒,而回测分数本身充满噪音。模型很容易顺着噪音漂走,最后产出的因子和最初那个经济学假设已经没什么关系,纯粹是过拟合 backtest 的副产品。
可信度不足。 大多数方法每轮都是基于当前 context 重新采样,没有显式地继承上一轮里被验证过的合理部分。这意味着没有可追溯的因子谱系,也无法解释"为什么这个因子是从那个想法演化来的"。审计和后续复用都成问题。
探索受限。 搜索倾向于在种子因子附近反复打转,越挖越像,最终塞满相似结构的因子,加剧 crowding。理论上的假设空间很大,实际覆盖的只是一小块。
QuantaAlpha 的回应是把视角从"单个因子"换成"整条挖掘轨迹",再借遗传算法的 mutation 和 crossover 来做演化。
QuantaAlpha 框架:四个组件,一条轨迹
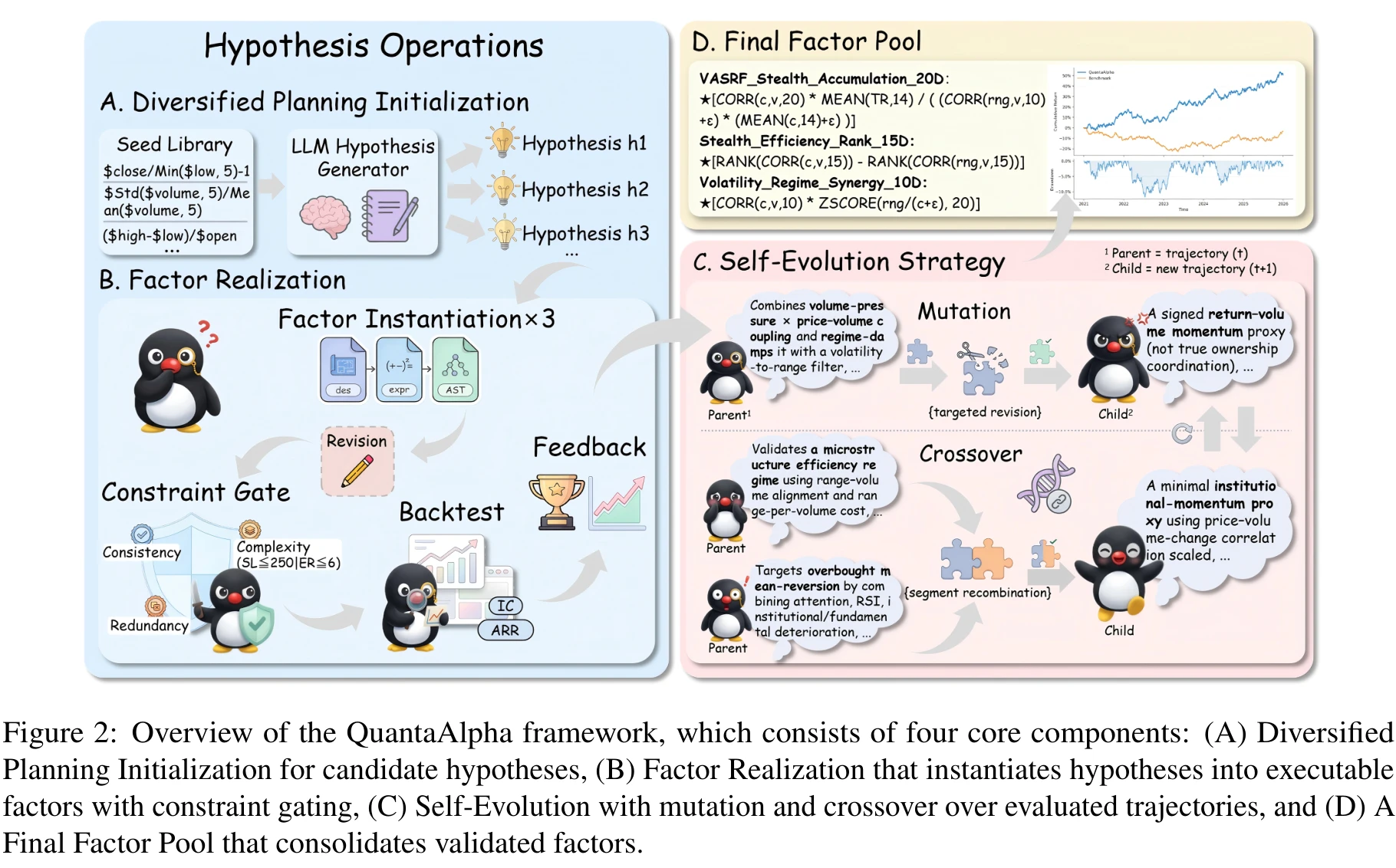
整个系统拆成四块:
- A. Diversified Planning Initialization:用一个 initialization agent 从种子库(Alpha158(20) 子集,按低相关性分组)出发,生成一批互补的初始假设。要求是覆盖不同信号来源(价/量)、不同时间尺度(短/长)、不同机制类型(动量/反转/状态切换),目的是把搜索前沿铺开。
- B. Factor Realization:假设→因子表达式→可执行代码的流水线,中间夹了 consistency / complexity / redundancy 三道闸。
- C. Self-Evolution:在已有 trajectory 之上,按奖励选择父代,用 mutation 局部改写、用 crossover 拼接高分片段,迭代生成更好的轨迹。
- D. Final Factor Pool:把演化过程中验证过的因子沉淀下来,最终交给下游 LightGBM 做组合。
后面分三部分展开:trajectory 的形式化、可控的因子构造、自进化机制。
Alpha 挖掘的轨迹形式化
传统形式化把因子挖掘写成:
$$ f^* = \arg\max_{f \in \mathcal{F}} \mathcal{L}\big(f(X), y\big) - \lambda R(f) $$QuantaAlpha 不在因子层面做优化,而是定义一条 mining trajectory:
$$ \tau = (s_0, a_0, s_1, a_1, \ldots, s_n) $$\(s_0\) 是初始上下文(市场数据、用户种子),\(a_i\) 是 multi-agent 在第 \(i\) 步采取的动作(生成假设、构造因子、修代码、回测),\(s_n\) 是终止状态,里面包含这次运行的回测结果。轨迹的奖励直接挂在终态上:
$$ R(\tau) = \mathcal{L}\big(f_\tau(X), y\big) - \lambda R(f_\tau) $$学习目标变成找一个轨迹生成策略 \(\pi\),让期望奖励最大:
$$ \pi^* = \arg\max_\pi \mathbb{E}_{\tau \sim \pi}\big[R(\tau)\big] $$这层抽象不只是包装。把每次完整运行当作一个可操作的对象之后,“哪一步出问题了"和"哪几段拼起来效果好"才变成可以局部干预的事情。论文里对 AlphaAgent、RD-Agent 的批评聚焦在"缺少可追溯的因子谱系"上,本质就是中间的决策链没有被保留下来供下一轮复用。
可控的因子构造:符号表达 + AST + 三道闸
直接让 LLM 写因子代码是脆的:语法错误、依赖不匹配、和假设对不上。QuantaAlpha 走了一条更"编译器"的路子。
符号表达 + AST。 先让 factor agent 把假设 \(h\) 映射成一个结构化语义描述 \(d\),再用预定义算子库 \(\mathcal{O}\) 组装成符号表达式 \(f\),然后解析成 AST \(T(f)\)。叶子绑到原始字段($high、$volume),内部节点是算子(TS_MIN、SMA、RANK),最后再编译成可执行代码 \(c\)。编译失败触发 LLM 局部修复,但要求保留语义。
一致性校验。 一个 verifier 检查两件事:假设 \(h\)、语义描述 \(d\)、符号表达式 \(f\) 是否对齐;符号定义 \(f\) 和代码 \(c\) 是否忠实。任何一处不一致就回去重写对应组件,最多重试若干次。这条闸主要堵的是"假设说捕捉流动性,代码里却没碰成交量"这种悄悄的语义漂移。
复杂度控制。 显式给出复杂度评分:
$$ C(f) = \alpha_1 \cdot SL(f) + \alpha_2 \cdot PC(f) + \alpha_3 \cdot \log\big(1 + |\mathcal{F}_f|\big) $$\(SL\) 是符号长度,\(PC\) 是自由参数个数(窗口、阈值),\(\mathcal{F}_f\) 是用到的特征集合。这套评分约束的是"看起来很厉害但其实在过拟合"的复杂式子。
冗余控制。 用 AST 同构子树匹配度量两个因子的结构相似度:
$$ s(f_i, f_j) = \max_{S_i \subseteq T(f_i),\, S_j \subseteq T(f_j),\, S_i \cong S_j} |V(S_i)| $$候选因子和已有 alpha zoo \(\mathcal{Z}\) 的最大相似度 \(S(f) = \max_{\zeta \in \mathcal{Z}} s(f, \zeta)\) 超阈值就拒掉。结构去重之后还会在 2021 验证集上做一次输出相关性过滤,相关性过高的留 RankIC 更高的那个。
这套"结构去重 + 输出去重"的两段式比单纯查 AST 更稳。只看结构的话,两个完全不同的 AST 可能在回测里行为高度相似(比如等价变形);只看输出又会把"看起来像但实质不同"的因子误删。两层一起卡才接近实际想要的"不重复”。
自进化:Mutation 和 Crossover 的具体做法
初始化阶段先跑出一批 trajectory \(\mathcal{T}_0 = \{\tau_j^0\}_{j=1}^{N_{init}}\)。之后每一轮都用两个原语演化。
Mutation:定点修复。 拿到一条 trajectory \(\tau\),先让 agent 做 self-reflection,定位最该背锅的那一步 \(k\),然后只重写 \(a_k\) 这一步(或一小段),前缀保持不动,后缀由 agent 在新前缀的条件下重新生成:
$$ \tau_{child} = \big(s_0, a_0, \ldots, s_k, \text{Refine}(a_k), s_{k+1}, a_{k+1}, \ldots, s_n\big) $$重写的内容可以是假设本身、符号表达式、或者编译后的代码。即便定位不完全准,这种"带方向的搜索"也比纯随机重生成更可能跳到一个不同的因子空间区域。这是 QuantaAlpha 真正起作用的归纳偏置:把上一次失败的具体环节当作信号,而不是当作噪音整个扔掉。
Crossover:拼接高分片段。 按奖励从 \(\mathcal{T}_{i-1}\) 里选出父代子集 \(\mathcal{P}_{i-1}\),再从 \(k\) 条父代里抽出"贡献高累计奖励的片段"(假设模板、构造模式、有效的修复动作之类),拼成一条新轨迹:
$$ \tau_{child} = \text{Crossover}\big(\tau^{(1)}, \ldots, \tau^{(k)}\big) $$这个原语的意义在于显式继承"被验证过的决策"。这一点直接回应了开头说的"可信度不足":crossover 出来的子轨迹是有谱系的,能解释清楚它从哪几个父代继承了哪些片段。
消融实验里 mutation 的贡献明显更大(IC 掉 0.0079,ARR 掉 1.26%),crossover 的影响小一些但稳定。论文的解释是当前只跑了 5 轮迭代,crossover 这种"重组复用"的收益需要更长的演化周期才能完全展开。
CSI 300 主实验:和 RD-Agent、AlphaAgent 的真实差距
数据集是 CSI 300,2016-01 至 2020-12 训练、2021 全年验证、2022-01 至 2025-12-26 测试(论文写到这个日期为止,刚好覆盖到去年年底)。所有 LLM 方法都把约 150 个验证过的因子喂给同一个 LightGBM 做下游组合,避免比"谁挑得好"。GPT-5.2 上的核心对比:
| 方法 | IC | Rank IC | ARR (%) | MDD (%) |
|---|---|---|---|---|
| RD-Agent | 0.0286 | 0.0250 | 3.58 | 16.76 |
| AlphaAgent | 0.0347 | 0.0334 | 1.11 | 13.89 |
| QuantaAlpha | 0.0472 | 0.0459 | 4.68 | 11.80 |
相对 RD-Agent,IC 提升 0.0186、ARR 多 1.10%、MDD 少 4.96%。论文的归因是 RD-Agent 没有任何生成阶段的正则化,而 QuantaAlpha 和 AlphaAgent 都有 generation-stage regularization(虽然两者的具体约束并不相同),所以 RD-Agent 的语义漂移和实现可靠性都更差。
相对 AlphaAgent(同样带生成阶段约束,主要是 AST 去重 + 假设对齐 + 复杂度),IC 再提升 0.0125、ARR 多 3.57%、MDD 少 2.09%。这部分增量来自 trajectory 级的自进化:mutation 拓宽机制层面的探索,crossover 复用已验证的构造模式,高质量因子的产出率和演化的稳定性一起被拉上来。
另一个细节:在 Claude-4.5-Sonnet 上 QuantaAlpha 的 IC 是 0.0445,比 DeepSeek-V3.2 的 0.0461 稍低,差距 0.0016 IC。论文给的解释是 Claude 的反馈输出更长,固定上下文预算下能塞进 prior trajectory 数变少,而且 mutation 倾向于局部小改;DeepSeek 反过来更敢做大跳跃。这种"模型性格影响 agent 行为"的观察在 LLM agent 论文里其实很少有人愿意写出来。
跨市场迁移与 alpha decay
![]()
CSI 300 上挖出来的因子,不做任何重新训练,直接拿到 CSI 500 和 S&P 500 上跑:CSI 500 累计超额 40.28%,S&P 500 累计超额 19.1%。能跨市场的原因被归到两点:因子用的是标准 OHLCV 算子,没有依赖特定市场的 micro-structure 字段;日级横截面归一化抹掉了不同市场的 scale 差异。
更有意思的是 alpha decay 的对比。图里 2023 年是 A 股一次明显的风格切换:之前几年靠机构抱团的"核心资产"驱动,传统动量/反转都管用;2023 年市场转向小盘和题材,日内噪音和隔夜跳空都变大,趋势的连续性变差。这一年 baseline 们集体扑街,Alpha158 的 IC 几乎归零。QuantaAlpha 在这次 regime shift 里仍然维持在 0.045 之上(从图 4 读数),几乎没有跌幅。论文给的解释是它挖出的因子(比如 Mean-Reverting Range Deviation:用近期高低价区间偏离做反转信号;Overnight Gap Structure:把隔夜跳空作为独立的信息消化窗口)反映的是更底层的微观结构特征,波动率聚集和隔夜信息消化在不同市值风格上都成立。
这是这篇论文里 most underrated 的结果:跨市场迁移看着亮眼,但跨 regime 稳定其实更难。前者只需要因子是"够通用的统计特征",后者要求因子捕捉到一种在不同市场状态下都成立的微观行为。
因子演化的迭代效率
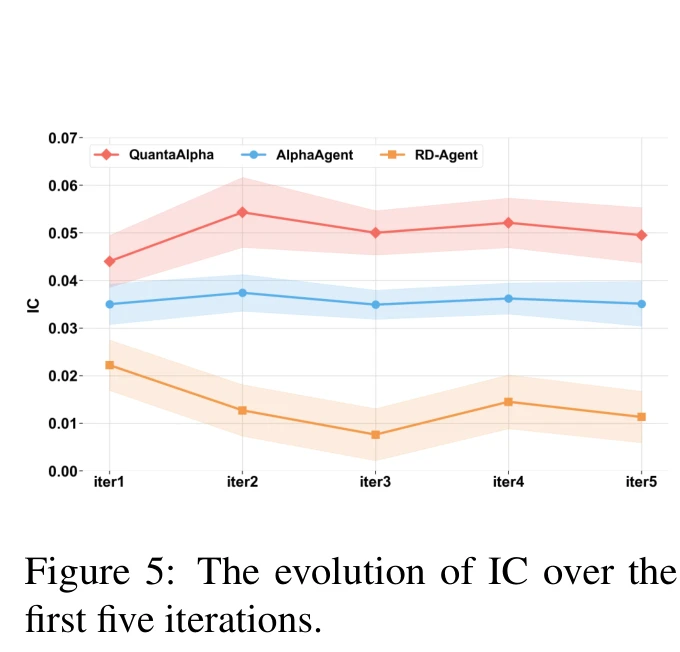
跨五轮迭代追踪 IC 分布。QuantaAlpha 在 iter 2 就把 IC 推到 0.054 附近,之后稳在 0.05 上下;AlphaAgent 一直在 0.035 横盘;RD-Agent 反而往下走,iter 3 跌到约 0.008(从图中读数)。这张图直接打脸了"LLM agent 多迭代就一定更好"的朴素假设:迭代要有收益,前提是有结构化的复用机制,否则就是把噪音放大。
论文还提了一个长程结果:在更长的演化窗口里,QuantaAlpha 的预测能力到大约第 15 轮才开始衰减。也就是说前 5 轮远没有摸到天花板,trajectory 级的演化在持续提供新的有效模式。
几条值得记住的判断
第一,因子挖掘的天花板不是单次生成的质量,而是"如何复用上一次验证过的决策"。AlphaAgent 和 RD-Agent 之所以迭代很快进入瓶颈,根源是每轮基本从头再来。QuantaAlpha 把 trajectory 显式保留下来做 mutation/crossover,是把这条隐性的反馈通道补上了。
第二,AST 同构子树匹配 + 输出相关性过滤这套两段式去重,比单纯查 AST 实用很多。结构去重负责把"换个包装的老因子"挡掉,输出去重负责把"长得不像但行为一样"的因子合并。两段都做才接近实际想要的去重语义。
第三,跨市场迁移和跨 regime 稳定是两件不同的事,后者更难也更值钱。zero-shot 迁移到 S&P 500 这种结果在 LLM 因子挖掘的论文里见得多了,但能在 A 股 2023 风格切换里保持 IC 稳定的方法很少。这个结果暗示挖到的因子触及了更底层的微观结构机制,不只是统计套利。
第四,模型选型直接改 agent 行为。同样的 QuantaAlpha 框架,Claude 给出小步长 mutation、DeepSeek 给出大跳跃,IC 差 0.0016。下次设计这种 agentic pipeline 时,“选哪个 base model"应该和"调哪个超参"放到同等优先级来考虑。
QuantaAlpha 的工程启示
在 LLM 因子挖掘这条线上,QuantaAlpha 给了一个相对干净的范式:把 alpha 挖掘建模成 trajectory 而非 factor,用 mutation/crossover 在 trajectory 空间里演化,再用一致性、复杂度、冗余三道闸守住生成质量。CSI 300 IC 0.0472 是当前能看到的最强结果之一,跨 regime 稳定性更难得。
如果只搬一件事到自己的 agent 系统里,先搬 mutation 的失败定位:让 agent 显式说出"上一轮是哪一步把整条 trajectory 拖低的”,然后只重写那一段。这件事不依赖任何特定 LLM,是 prompt 设计层面就能落地的改动。crossover 的收益需要更长的演化窗口,做完 mutation 再考虑。