量化交易的文章里总会冒出一些数学术语:对数收益率、标准差、协方差矩阵、OLS 回归、偏导数。逐个去查定义当然可以,但缺少量化交易的语境,查完还是不知道"这个数学工具到底在干嘛"。下面把量化交易中最常用的数学概念集中过一遍,每个配一个交易场景和 Python 代码。
对数收益率
股票从 100 涨到 110,收益率怎么算?
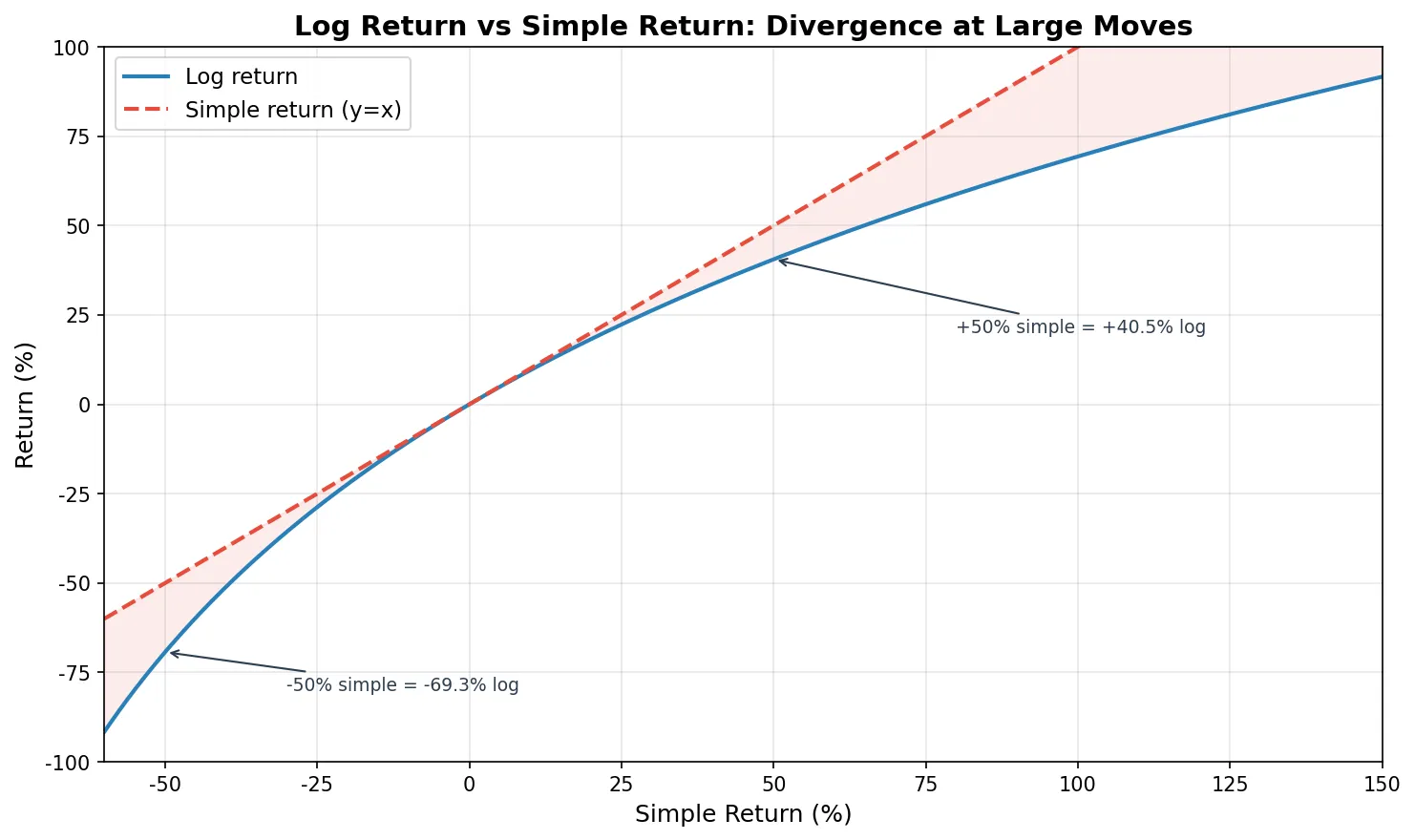
最直观的算法是简单收益率(simple return):\((110 - 100) / 100 = 10\%\)。但量化交易里几乎都用对数收益率(log return):\(\ln(110 / 100) = 9.53\%\)。
公式对比:
$$ R_{\text{simple}} = \frac{P_t - P_{t-1}}{P_{t-1}} = \frac{P_t}{P_{t-1}} - 1 $$$$ R_{\text{log}} = \ln\left(\frac{P_t}{P_{t-1}}\right) $$为什么量化偏爱 log return?三个原因。
可加性。简单收益率不能直接加。一只股票先涨 10% 再跌 10%,简单收益率加起来是 0%,但实际你亏了 1%(100 → 110 → 99)。对数收益率可以直接加:多期的对数收益率之和 = 整段时间的对数收益率。这在计算累计收益、滚动窗口指标时省掉很多麻烦。
对称性。简单收益率里,涨 50%(100→150)和跌 33.3%(150→100)是"对称"的操作,但数字不对称。对数收益率里,涨是 +40.5%,跌是 -40.5%,完美对称。
小变动时近似相等。日收益率通常在 ±2% 以内,这个范围里两种收益率几乎一样(差不到 0.02 个百分点)。换句话说,日常使用没区别,但在数学性质上 log return 好用得多。
import numpy as np
prices = np.array([100, 110, 104.5, 120, 96])
simple_ret = np.diff(prices) / prices[:-1]
log_ret = np.log(prices[1:] / prices[:-1])
for i in range(len(simple_ret)):
print(f"Day {i+1}: simple={simple_ret[i]*100:+.2f}% "
f"log={log_ret[i]*100:+.2f}%")
print(f"\nSum of simple returns: {simple_ret.sum()*100:.2f}%")
print(f"Sum of log returns: {log_ret.sum()*100:.2f}%")
print(f"Actual total return: {(prices[-1]/prices[0]-1)*100:.2f}%")
print(f"exp(sum of log ret): {(np.exp(log_ret.sum())-1)*100:.2f}%")
Day 1: simple=+10.00% log=+9.53%
Day 2: simple=-5.00% log=-5.13%
Day 3: simple=+14.83% log=+13.83%
Day 4: simple=-20.00% log=-22.31%
Sum of simple returns: -0.17%
Sum of log returns: -4.08%
Actual total return: -4.00%
exp(sum of log ret): -4.00%
简单收益率加起来是 -0.17%,但股票实际跌了 4%。对数收益率加起来是 -4.08%,转换回来(exp)正好是 -4.00%。这就是可加性的实际价值。
注意:波动越大,两种收益率差距越大。Day 4 跌了 20%,简单收益率是 -20%,对数收益率是 -22.31%,差了 2.31 个百分点。加密货币市场日波动经常超过 10%,这个差距更明显。
均值、方差和标准差
均值(mean) 衡量"平均赚多少",标准差(standard deviation) 衡量"赚得稳不稳"。量化交易里,收益和风险就是用这两个数字定义的。
均值和标准差的公式:
$$ \mu = \frac{1}{n}\sum_{i=1}^{n} r_i, \quad \sigma = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(r_i - \mu)^2} $$夏普比率(Sharpe Ratio) 是均值和标准差最经典的组合:
$$ \text{Sharpe} = \frac{\mu - R_f}{\sigma} $$分子是超额收益(减去无风险利率),分母是波动率。直觉上就是"每承担一单位风险,赚了多少超额收益"。夏普 1.0 算不错,2.0 以上很优秀,低于 0.5 基本不值得承担那个波动。
年化是一个经常搞混的细节。日收益率的均值乘 252(交易日数)得到年化收益率,日标准差乘 \(\sqrt{252}\) 得到年化波动率。为什么标准差是乘根号而不是直接乘?因为独立随机变量的方差是可加的(\(\text{Var}(X_1 + X_2) = \text{Var}(X_1) + \text{Var}(X_2)\)),所以 252 天的方差 = 单日方差 × 252,标准差就是乘 \(\sqrt{252}\)。
import numpy as np
np.random.seed(42)
daily_returns = np.random.normal(0.0004, 0.015, 252)
mean_daily = daily_returns.mean()
std_daily = daily_returns.std(ddof=1) # ddof=1: sample std
rf_daily = 0.04 / 252 # 4% annual risk-free rate
sharpe = (mean_daily - rf_daily) / std_daily * np.sqrt(252)
annual_return = mean_daily * 252
annual_vol = std_daily * np.sqrt(252)
print(f"Annual return: {annual_return*100:.2f}%")
print(f"Annual volatility: {annual_vol*100:.2f}%")
print(f"Sharpe ratio: {sharpe:.2f}")
Annual return: 8.66%
Annual volatility: 23.03%
Sharpe ratio: 0.20
年化收益 8.66%,波动率 23.03%,夏普只有 0.20。这意味着收益几乎全被波动吃掉了,风险调整后的回报很低。
正态分布与肥尾
正态分布(Normal Distribution) 是量化交易里最常用的假设。它的概率密度函数:
$$ f(x) = \frac{1}{\sigma\sqrt{2\pi}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) $$正态分布有一个好记的经验法则:68% 的数据落在 \(\mu \pm 1\sigma\) 内,95% 落在 \(\mu \pm 2\sigma\),99.7% 落在 \(\mu \pm 3\sigma\)。换句话说,超过 3σ 的极端事件在正态分布下概率只有 0.3%,大约一年才发生一次。
问题是,股票收益率不是严格正态的。
真实的收益率分布比正态分布有更厚的尾巴,统计学上叫肥尾(fat tails) 或尖峰厚尾(leptokurtic)。3σ 以外的极端事件实际发生的频率远高于正态分布的预测。用模拟数据做个对比:正态分布预测 5000 个交易日里只有 14 次超过 3σ 的事件,但有肥尾特征的收益率分布里,这个数字可以到 60-80 次,是正态预测的 4-5 倍。
这和风险管理直接相关。VaR(Value at Risk) 是最常用的风控指标之一,很多 VaR 计算假设收益率服从正态分布。如果实际分布有肥尾,正态 VaR 就会严重低估极端亏损的概率。2008 年次贷危机中很多量化基金爆仓,一个核心原因就是模型假设了正态分布,而市场给出了"不可能发生"的 6σ 甚至 10σ 事件。2020 年 3 月也是一个例子:标普 500 一周之内多次出现超过 4σ 的单日波动。
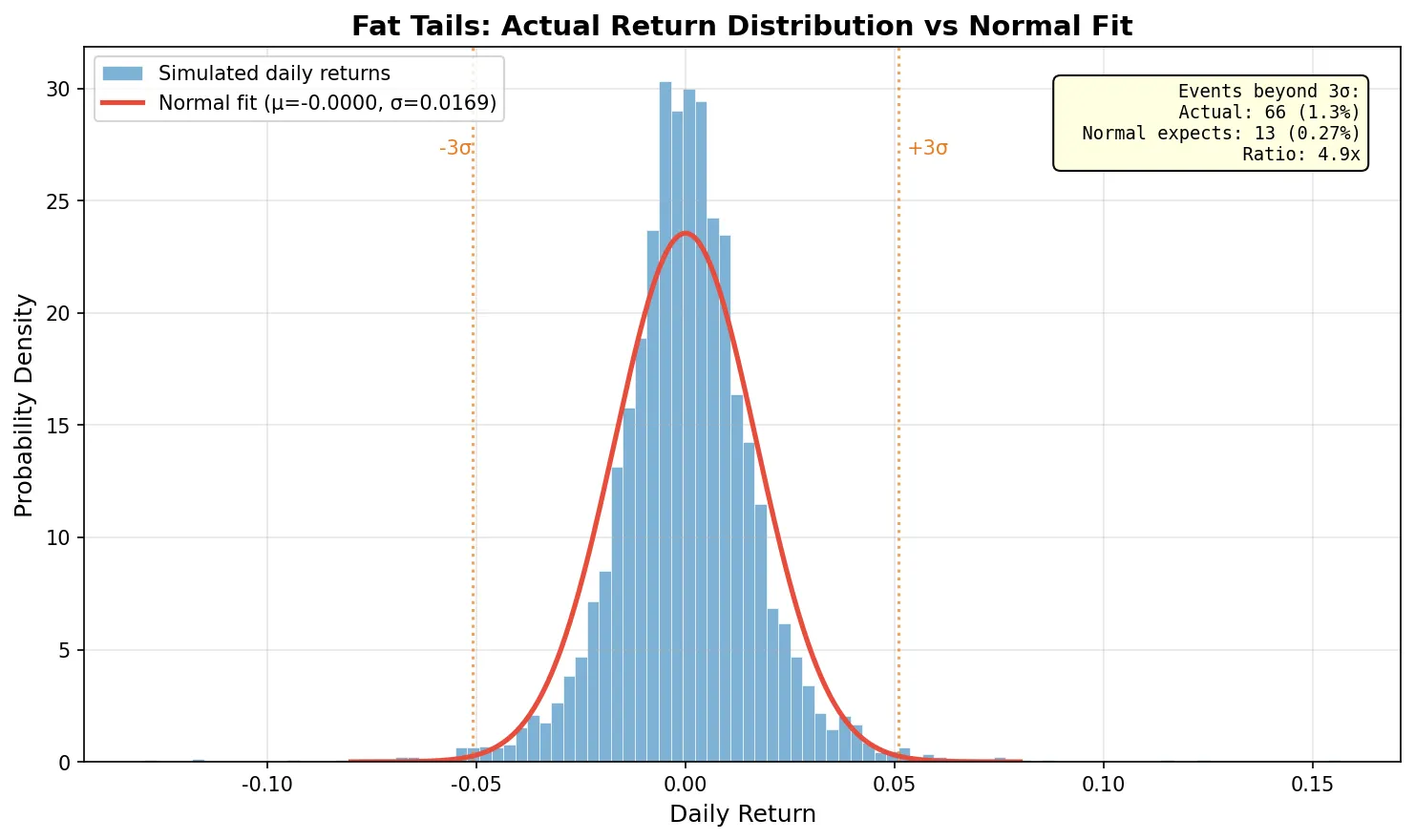
图中蓝色是模拟的有肥尾特征的收益率分布,红色线是用相同均值和标准差拟合的正态分布。尾部明显超出正态预测:3σ 之外的实际事件数量是正态预测的好几倍。
协方差与相关系数
单只股票用均值和标准差就够了。两只以上的股票放在一起,就需要协方差(covariance) 来描述它们之间的关系。
$$ \text{Cov}(A, B) = \frac{1}{n-1}\sum_{i=1}^{n}(A_i - \bar{A})(B_i - \bar{B}) $$协方差为正,说明两只股票倾向于同涨同跌;为负,说明一只涨的时候另一只倾向于跌。但协方差的数值大小不直观(和收益率的量级有关),所以通常用相关系数(correlation) 来标准化:
$$ \rho_{A,B} = \frac{\text{Cov}(A, B)}{\sigma_A \cdot \sigma_B}, \quad \rho \in [-1, 1] $$\(\rho = 1\) 完全正相关,\(\rho = -1\) 完全负相关,\(\rho = 0\) 不相关。
把 N 个资产两两之间的协方差排成一个 \(N \times N\) 的矩阵,就是协方差矩阵 \(\Sigma\)。这个矩阵在量化交易里到处都在用:配对交易用相关系数找联动股票,投资组合优化用协方差矩阵计算组合风险,因子模型用协方差结构分析因子之间的关系。
投资组合方差的公式用矩阵写很紧凑,但先看一个两个资产的例子更直观。假设你 60% 仓位在股票 A(年化波动率 20%),40% 在股票 B(年化波动率 15%),两者相关系数 0.3。组合方差:
$$ \sigma_p^2 = 0.6^2 \times 0.20^2 + 0.4^2 \times 0.15^2 + 2 \times 0.6 \times 0.4 \times 0.20 \times 0.15 \times 0.3 = 0.02232 $$组合波动率 \(\sigma_p = \sqrt{0.02232} = 14.94\%\)。如果两者完全正相关(\(\rho = 1\)),组合波动率是 18%(加权平均)。相关系数 0.3 让波动率从 18% 降到了 14.94%,这就是分散投资的数学本质。不过有个坑:相关系数在市场平稳时看着很稳定,一到暴跌行情就集体飙向 1.0。2020 年 3 月美股熔断那几天,股票、商品、信用债的相关性全部拉满,分散投资在最需要它的时候失效了。用历史相关系数做组合优化时,这一点要记住。
推广到 N 个资产,公式写成矩阵形式:
$$ \sigma_p^2 = \mathbf{w}^T \Sigma \mathbf{w} $$其中 \(\mathbf{w}\) 是各资产的权重向量,\(\Sigma\) 是协方差矩阵。
import numpy as np
np.random.seed(2024)
n = 252
stock_a = np.random.normal(0.0005, 0.02, n)
stock_b = 0.6 * stock_a + np.random.normal(0.0002, 0.015, n)
stock_c = -0.3 * stock_a + np.random.normal(0.0003, 0.018, n)
returns = np.column_stack([stock_a, stock_b, stock_c])
cov_matrix = np.cov(returns.T)
corr_matrix = np.corrcoef(returns.T)
labels = ['Stock A', 'Stock B', 'Stock C']
print("=== Correlation Matrix ===")
for i, label in enumerate(labels):
row = ' '.join(f'{corr_matrix[i,j]:+.4f}' for j in range(3))
print(f" {label}: {row}")
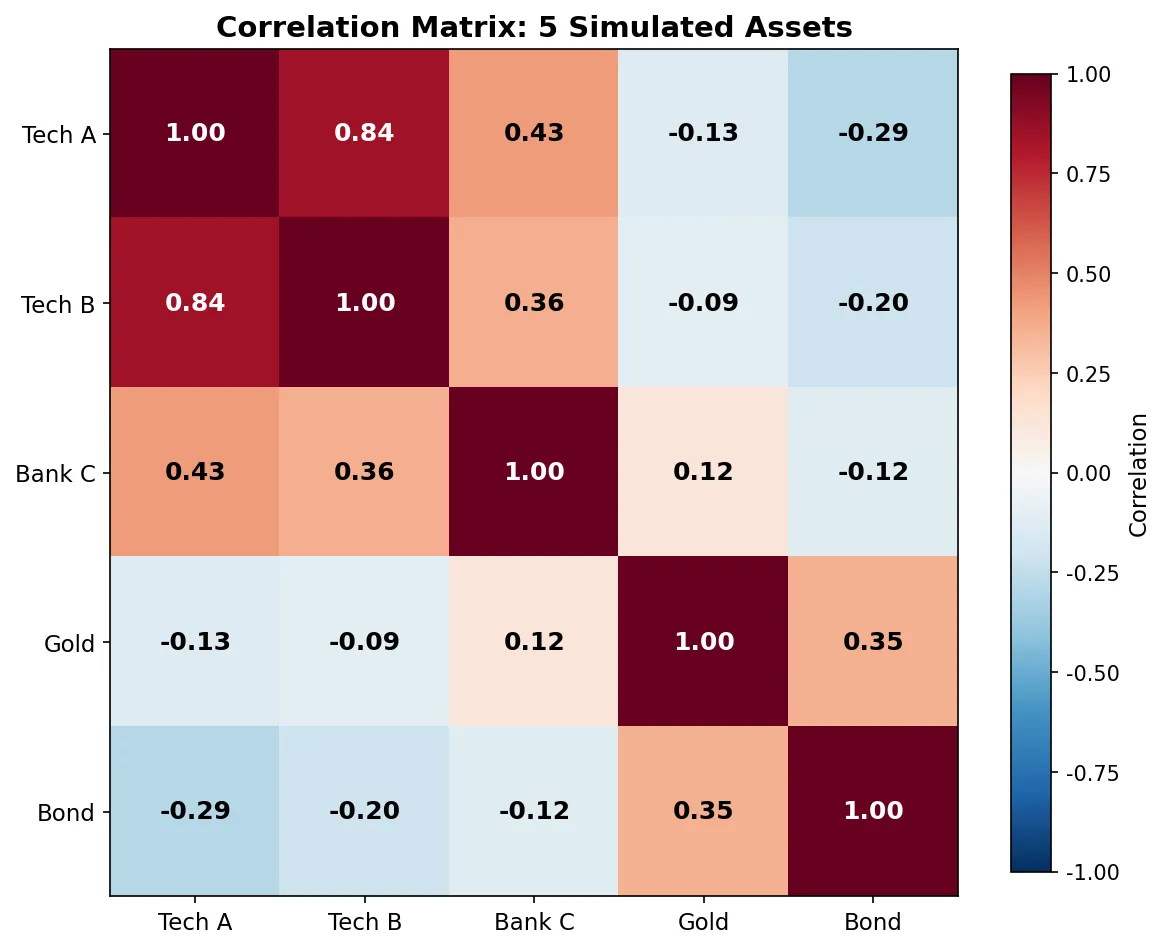
=== Correlation Matrix ===
Stock A: +1.0000 +0.5393 -0.4396
Stock B: +0.5393 +1.0000 -0.1537
Stock C: -0.4396 -0.1537 +1.0000
Stock A 和 B 相关系数 +0.54(中等正相关,同涨同跌为主),A 和 C 相关系数 -0.44(负相关,走势相反)。如果你的组合里只有 A 和 B,风险分散效果有限;加入 C 这种负相关资产,组合波动率能降不少。
线性回归 OLS
OLS(Ordinary Least Squares,最小二乘法) 是量化交易里用得最多的统计工具。核心思想很简单:给定一堆数据点,找一条直线让所有数据点到直线的"距离"(残差的平方和)最小。
对于 \(y = \alpha + \beta x + \varepsilon\),OLS 的解是:
$$ \hat{\beta} = \frac{\sum(x_i - \bar{x})(y_i - \bar{y})}{\sum(x_i - \bar{x})^2} $$多变量的矩阵形式:
$$ \hat{\boldsymbol{\beta}} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y} $$量化里 OLS 最常见的两个场景:
因子回归。Fama-French 因子模型就是用 OLS 把基金收益拆解成市场、规模、价值等因子的贡献。回归出来的 \(\alpha\) 代表因子解释不了的超额收益,\(\beta\) 代表对各因子的暴露程度。
配对交易。两只相关股票 A 和 B,用 OLS 回归 \(A = \alpha + \beta B + \varepsilon\),残差 \(\varepsilon\) 就是价差。价差偏离均值太远就做均值回归交易。
import numpy as np
np.random.seed(42)
n = 120 # 10 years monthly
market = np.random.normal(0.008, 0.045, n)
fund = 0.002 + 1.15 * market + np.random.normal(0, 0.015, n)
X = np.column_stack([np.ones(n), market])
beta, _, _, _ = np.linalg.lstsq(X, fund, rcond=None)
pred = X @ beta
ss_res = np.sum((fund - pred) ** 2)
ss_tot = np.sum((fund - fund.mean()) ** 2)
r2 = 1 - ss_res / ss_tot
mse = ss_res / (n - 2)
se = np.sqrt(np.diag(mse * np.linalg.inv(X.T @ X)))
t_stats = beta / se
print(f"Alpha: {beta[0]*100:.3f}% /month (t={t_stats[0]:.2f})")
print(f"Beta: {beta[1]:.3f} (t={t_stats[1]:.2f})")
print(f"R²: {r2:.4f}")
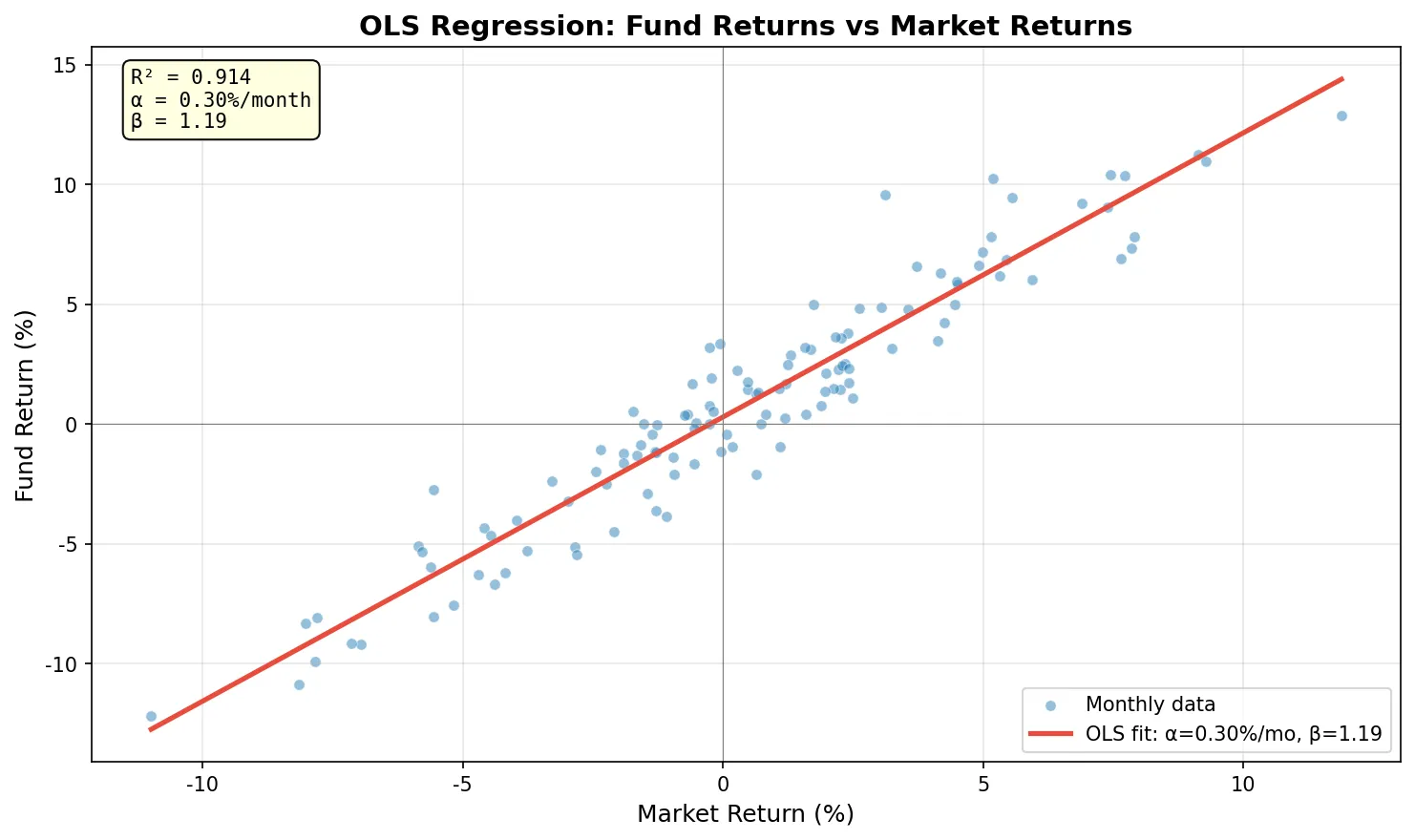
Alpha: 0.296% /month (t=2.12)
Beta: 1.186 (t=35.50)
R²: 0.9144
Beta 1.186 说明这只基金比大盘波动更大(市场涨 1%,基金平均涨 1.19%)。Alpha 0.296%/月,t 值 2.12,在 5% 显著性水平下勉强显著,说明有一定的超额收益但不算很确定。R² 0.91 说明市场因子解释了 91% 的基金收益变动。
两个常见误区。R² 高不代表预测准。R² = 0.91 看着很高,但这只说明"过去拟合得好",不保证未来。很多过拟合的模型 R² 接近 1.0,样本外照样崩。相关不代表因果。两只股票高度相关可能是因为它们都受同一个行业因子驱动,直接用一只预测另一只是危险的。
导数和偏导数
导数(derivative) 衡量的是函数的变化率。\(f'(x)\) 告诉你"x 变一点点,f(x) 变多少"。
期权的价格受多个变量影响:标的价格 \(S\)、到期时间 \(t\)、波动率 \(\sigma\)、利率 \(r\)。偏导数(partial derivative) 就是固定其他变量不动,只看一个变量变化对期权价格的影响。
期权交易者天天盯着的 Greeks 就是偏导数:
$$ \Delta = \frac{\partial V}{\partial S}, \quad \Theta = \frac{\partial V}{\partial t}, \quad \text{Vega} = \frac{\partial V}{\partial \sigma} $$\(\Delta = 0.6\) 的意思是:标的价格涨 $1,期权价格大约涨 $0.60。\(\Theta = -0.05\) 的意思是:每过一天,期权价格大约跌 $0.05(时间损耗)。Vega = 0.15 的意思是:隐含波动率涨 1 个百分点,期权价格大约涨 $0.15。
不需要手推 Black-Scholes 公式来理解 Greeks。核心直觉就一句话:Greeks 量化了期权价格对各个输入变量的敏感度。交易者用 Delta 决定对冲多少股票,用 Theta 评估时间衰减成本,用 Vega 判断波动率变化的风险。具体的 Greeks 计算和应用,可以看期权 Greeks 系列。
如果你想用代码验证,最简单的方法是有限差分(finite difference):把标的价格加一点点(比如 $0.01),算两次期权价格,取差值除以步长,就得到 Delta 的数值近似。这和偏导数的定义 \(\frac{\partial V}{\partial S} \approx \frac{V(S+h) - V(S-h)}{2h}\) 完全一致。
数学概念速查表
| 数学概念 | 一句话解释 | 量化应用场景 |
|---|---|---|
| 对数收益率 | \(\ln(P_t/P_{t-1})\),可直接加总 | 累计收益计算、收益率建模 |
| 均值 | 平均收益率 | 策略期望收益 |
| 标准差 | 收益率的离散程度 | 波动率、风险度量 |
| 夏普比率 | 超额收益 / 标准差 | 策略风险调整后表现 |
| 正态分布 | 钟形曲线分布 | VaR 计算、风险建模 |
| 肥尾 | 极端事件比正态更频繁 | 尾部风险管理 |
| 协方差 | 两资产联动方向和强度 | 配对交易、组合优化 |
| 相关系数 | 标准化的协方差,[-1, 1] | 找联动/对冲标的 |
| 协方差矩阵 | N 资产关系的 N×N 矩阵 | 投资组合风险计算 |
| OLS 回归 | 最小化残差平方和的直线拟合 | 因子回归、配对交易价差 |
| R² | 模型解释了多少比例的变动 | 模型拟合度评估 |
| 偏导数 | 固定其他变量的变化率 | 期权 Greeks |
概率统计处理的是"这个策略的收益和风险是什么",线性回归回答"收益从哪来",偏导数告诉你"参数变了会怎样"。量化交易的数学不需要从头学一遍大学课程,搞清楚这张表里的概念,读公式就不会卡住了。