Qlib 是微软开源的 AI 量化投资平台,2020 年发布,到现在 GitHub 上 16k+ star。它把数据、因子、模型、回测、报告打成一条流水线,标配了 Alpha158/Alpha360 两个常用因子集,自带 LightGBM、Transformer、TCN 等 20 多个模型。这篇 Qlib 教程从安装讲到跑通第一个 LightGBM + Alpha158 策略,再到看懂回测报告,最后给一份踩坑清单。
读完你能做到:本机装好 Qlib,下载 A 股日线数据,用 30 行代码训出一个模型,用 qrun 跑一遍标准化工作流,看懂输出的 IC、年化、最大回撤这些数字。
Qlib 是什么,什么时候该用它
Qlib 的定位是 “AI-oriented quantitative investment platform”,关键词是 AI 和 quant。它不是一个交易引擎(不像 vnpy 那样直连券商接口下单),也不是单纯的回测库(不像 backtrader 那样只关心策略逻辑)。Qlib 假设你的工作流是:拿历史数据 → 算因子 → 训模型 → 用模型打分排序 → 按排序构建组合 → 回测 → 看报告。这条流水线里每一环它都给了开箱即用的实现。
下面这张表是几个常见框架的横向对比,按我的实际使用经验整理:
| 框架 | 强项 | 弱项 | 典型用户 |
|---|---|---|---|
| Qlib | 因子工程 + ML 训练 + 回测一体化,A 股数据好下 | 学习曲线陡,框架抽象层多 | 量化研究员、做因子挖掘 |
| Backtrader | 灵活,事件驱动回测干净 | 没有数据、没有因子库,要自己造 | 策略开发者、CTA 做手 |
| vnpy | 实盘对接好,UI 全 | 偏交易系统,研究功能弱 | 国内私募实盘 |
| Zipline | 经典,文档全 | 已停止维护,pandas 老版本绑定 | 历史项目维护 |
| QuantConnect/LEAN | 云端一站式,多市场 | 闭源云服务,本地折腾难 | 海外散户、小团队 |
什么场景不适合用 Qlib:你只想跑一个简单的双均线策略、不需要 ML,那 Qlib 太重;你做高频或日内 tick 级,Qlib 的 1min 数据支持有但不是它的主战场;你要做实盘自动化下单,Qlib 没这个功能,得自己接。
安装 Qlib 与下载数据
最快的方式是 pip:
pip install pyqlib
Python 版本建议 3.8 到 3.11 之间。3.12 我实测在 Windows 上装 lightgbm 会偶尔翻车,3.8 下 pytorch 又找不到新版 wheel。3.10 是最稳的。
源码安装适合需要改 Qlib 内部代码的人:
git clone https://github.com/microsoft/qlib.git
cd qlib
pip install numpy cython
pip install -e .
注意官方 README 还在用 python setup.py install,setuptools 58+ 已经废弃了这个命令,会报 error: invalid command 'install'。改用 pip install -e . 是稳的,顺带支持后续改源码热更新。
装完用一行验证:
import qlib
print(qlib.__version__) # 0.9.x
接下来下载数据。Qlib 把 OHLCV 存成自己的 .bin 列式格式(速度比 csv/parquet 都快),需要先用脚本拉下来:
# A 股日线
python -m qlib.run.get_data qlib_data \
--target_dir ~/.qlib/qlib_data/cn_data \
--region cn
# 美股日线
python -m qlib.run.get_data qlib_data \
--target_dir ~/.qlib/qlib_data/us_data \
--region us
A 股全量大概 2GB 左右,国内网络偶尔断,加个 --interval 1d 显式指定频率,断了重跑会续传。下载完目录长这样:
~/.qlib/qlib_data/cn_data/
├── calendars/ # 交易日历
├── instruments/ # 股票池定义(all.txt, csi300.txt, csi500.txt)
├── features/ # 每只股票一个文件夹,里面是 .bin 列文件
└── dataset_cache/
Windows 用户注意一个坑:~ 在某些 shell 下不会展开,建议直接写绝对路径 D:/qlib_data/cn_data,并在后续代码里用同样的路径,免得 Qlib 找不到数据报 FileNotFoundError。
30 行代码跑通第一个 LightGBM 模型
下面这段是最小可运行的 Qlib 教程示例,从初始化到训练到打分一气呵成:
import qlib
from qlib.constant import REG_CN
from qlib.contrib.data.handler import Alpha158
from qlib.contrib.model.gbdt import LGBModel
from qlib.data.dataset import DatasetH
qlib.init(provider_uri="~/.qlib/qlib_data/cn_data", region=REG_CN)
handler = Alpha158(
instruments="csi300",
start_time="2017-01-01",
end_time="2023-12-31",
fit_start_time="2017-01-01",
fit_end_time="2020-12-31",
)
dataset = DatasetH(
handler=handler,
segments={
"train": ("2017-01-01", "2020-12-31"),
"valid": ("2021-01-01", "2021-12-31"),
"test": ("2022-01-01", "2023-12-31"),
},
)
model = LGBModel(
loss="mse",
learning_rate=0.05,
num_leaves=210,
feature_fraction=0.8879,
early_stopping_rounds=50,
num_boost_round=1000,
)
model.fit(dataset)
pred = model.predict(dataset)
print(pred.head())
跑通了你会看到一个 MultiIndex 的 Series,(datetime, instrument) 作为索引,值是模型对每只股票第二天收益的预测分数。CSI300 + Alpha158 + 默认 LGBModel 在 2022-2023 测试段上 IC 大概 0.04-0.06,Rank IC 0.05-0.07,这是个合理的 baseline,比随机(IC≈0)好,但远谈不上能直接赚钱。
第一次跑会花几分钟,因为 Alpha158 要把 158 个因子算一遍并缓存到 ~/.qlib/dataset_cache/。后面再跑同样的 handler 配置,直接走缓存秒开。
理解 Qlib 的核心架构:DataServer 与表达式引擎
跑通了示例,回过头看架构会清晰很多。Qlib 分四层,每层职责单一:
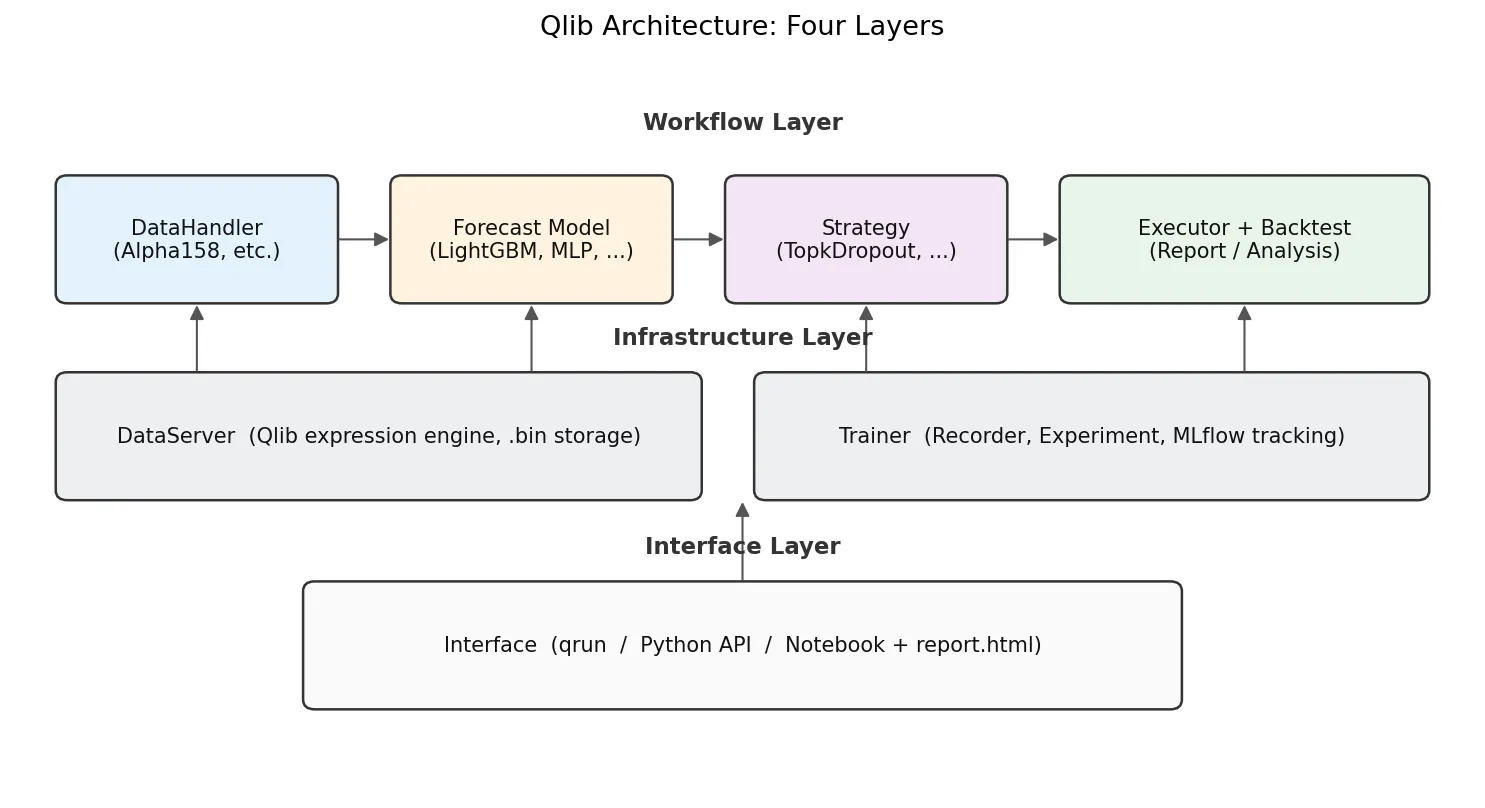
- DataServer:底层数据服务。负责从
.bin列文件里把原始 OHLCV 读出来,并实现一套表达式引擎。Mean($close, 5)这种字符串它能解析成对 close 列做 5 天均值的算子。 - DataHandler:把原始数据加工成 (features, labels) 这对 ML 训练能直接用的张量。Alpha158 就是一个内置的 DataHandler,它把 158 个表达式写死在源码里。
- Model:纯 ML 部分。Qlib 内置了 LightGBM、XGBoost、MLP、LSTM、GRU、Transformer、Localformer、TCN、TabNet、ADD、ADARNN、HIST 等等,统一接口
fit(dataset)/predict(dataset)。 - Strategy + Executor:把模型的预测分数转成实际持仓和订单,再用历史价格回放回测。最常用的
TopkDropoutStrategy后面单独讲。 - Recorder/Analyser:MLflow 风格的实验记录,每次
qrun自动存一份预测、持仓、报告 HTML。
DataHandler 里面发生了什么值得单独看一眼:
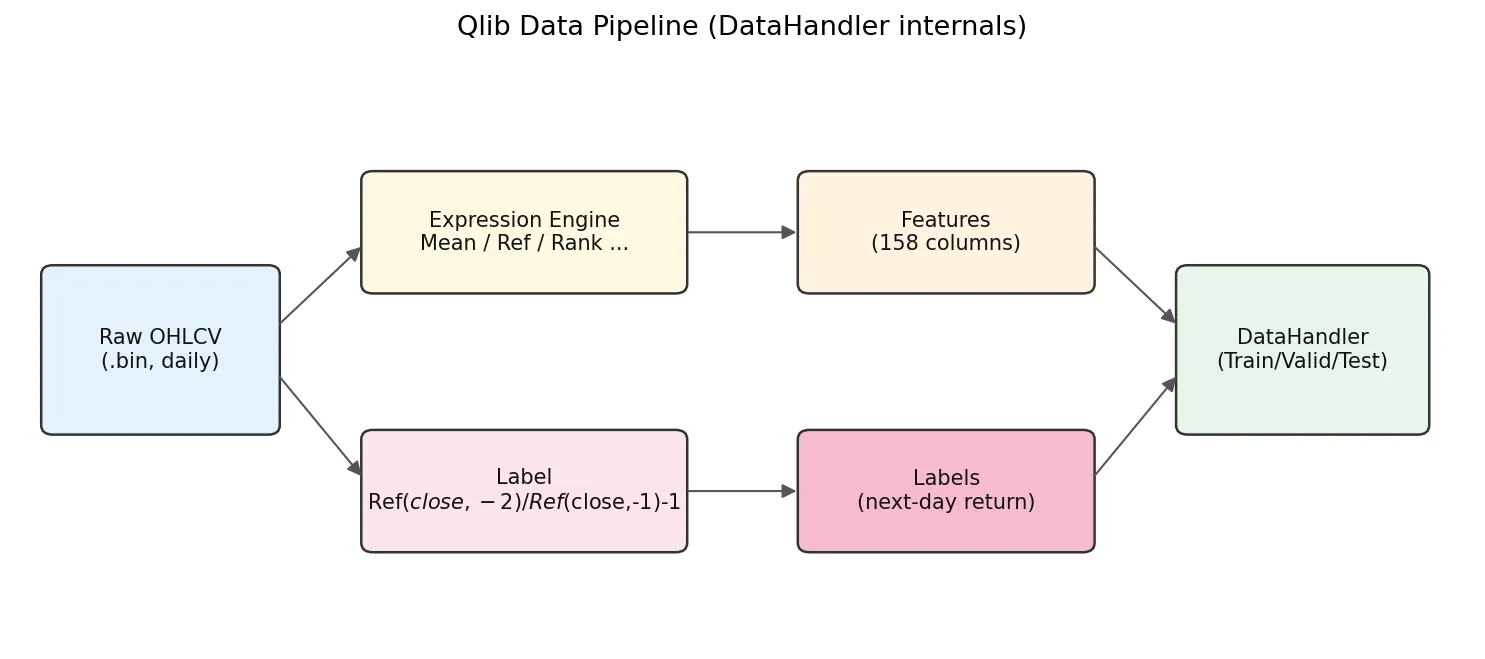
原始 .bin 数据进来,表达式引擎根据配置算出 158 个特征列,同时根据 label 表达式算出标签列,然后切分成 train/valid/test 三段交给模型。
默认 label 是 Ref($close, -2)/Ref($close, -1) - 1。负数偏移在 Qlib 里表示未来:Ref($close,-1) 是 T+1 的收盘,Ref($close,-2) 是 T+2 的收盘,所以这个标签是 T+1 收盘到 T+2 收盘的收益。配合 TopkDropoutStrategy 在 T 日决策、deal_price=close,相当于用模型在 T 日预测 T+1 到 T+2 这一天的持仓收益。换句话说,T 日盘后才能拿到所有特征(包含 T 日 close),决策也只能在盘后做,最早的成交是 T+1 的 close。任何把 T 日特征拿去 T 日内成交的实现都会引入 lookahead。
Alpha158 因子集详解
Alpha158 是 Qlib 默认的因子集,源码在 qlib/contrib/data/handler.py 和 qlib/contrib/data/loader.py。158 个因子按构造方式分几类:
| 类别 | 典型表达式 | 含义 |
|---|---|---|
| KBAR(K 线形态,9 个) | ($close-$open)/$open | 当日涨跌幅、上下影线相对长度 |
| ROC / MA(动量与均价偏离) | Mean($close, 5)/$close, Ref($close,5)/$close | 5/10/20/30/60 日窗口 |
| STD / BETA / RSQR / RESI(波动与拟合残差) | Std($close/Ref($close,1)-1, 20) | 收益率波动、对市场的回归残差 |
| MAX / MIN / QTLU / QTLD(极值与分位) | Max($high, 20)/$close | 距离 N 日高低点、上下四分位 |
| RANK / RSV(时序排名与位置) | Rank($close, 5) | N 日内当前收盘的位次 |
| IMAX / IMIN / IMXD(极值出现位置) | IdxMax($high, 20)/20 | 高点离今天有多远 |
| CORR / CORD(量价相关) | Corr($close, Log($volume+1), 5) | 价与对数成交量的相关 |
| CNTP / CNTN / CNTD / SUMP / SUMN / SUMD(涨跌天数与累计) | Mean($close>Ref($close,1), 20) | 20 日内涨天占比 |
| VMA / VSTD / WVMA / VSUMP 等成交量族 | Std($volume, 20)/$volume | 量能波动 |
每个因子的命名规则是 <算子>+<窗口>,比如 MA5 是 5 日均价比、STD20 是 20 日波动率比、ROC10 是 10 日变化率。看完整列表:
from qlib.contrib.data.loader import Alpha158DL
fields, names = Alpha158DL.get_feature_config()
for f, n in zip(fields, names):
print(f"{n:12s} = {f}")
会打印出所有 158 个表达式。这比翻文档快。
实际跑过几轮就会发现,158 个因子的贡献度极不均匀。在我自己的 CSI300 实验里,动量类(ROC、MA 偏离族)大约贡献了 IC 的一半以上,KBAR 那 9 个长期 IC 接近 0,量价相关(CORR、CORD)信噪比最差,单独训练时几乎是噪声。这和 LightGBM 的 feature importance 排名也对得上。所以拿 Alpha158 当 baseline 没问题,但别幻想 158 个因子真都在工作,大概率你的模型只在用其中 30-50 个。
另外 Alpha158 全是 OHLCV 衍生量,没有任何基本面、舆情、宏观数据。要做基本面因子,得自己写 DataHandler。
用 qrun + YAML 跑标准化工作流
写脚本调函数适合探索,但论文复现、批量实验更适合 YAML 配置 + qrun 命令行。Qlib 仓库里 examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml 就是一个完整模板:
qlib_init:
provider_uri: "~/.qlib/qlib_data/cn_data"
region: cn
market: &market csi300
benchmark: &benchmark SH000300
data_handler_config: &data_handler_config
start_time: 2008-01-01
end_time: 2020-08-01
fit_start_time: 2008-01-01
fit_end_time: 2014-12-31
instruments: *market
task:
model:
class: LGBModel
module_path: qlib.contrib.model.gbdt
kwargs:
loss: mse
colsample_bytree: 0.8879
learning_rate: 0.0421
subsample: 0.8789
lambda_l1: 205.6999
lambda_l2: 580.9768
max_depth: 8
num_leaves: 210
num_threads: 20
dataset:
class: DatasetH
module_path: qlib.data.dataset
kwargs:
handler:
class: Alpha158
module_path: qlib.contrib.data.handler
kwargs: *data_handler_config
segments:
train: [2008-01-01, 2014-12-31]
valid: [2015-01-01, 2016-12-31]
test: [2017-01-01, 2020-08-01]
record:
- class: SignalRecord
module_path: qlib.workflow.record_temp
- class: SigAnaRecord
module_path: qlib.workflow.record_temp
- class: PortAnaRecord
module_path: qlib.workflow.record_temp
kwargs:
config:
strategy:
class: TopkDropoutStrategy
module_path: qlib.contrib.strategy
kwargs:
topk: 50
n_drop: 5
backtest:
start_time: 2017-01-01
end_time: 2020-08-01
account: 100000000
benchmark: *benchmark
exchange_kwargs:
freq: day
limit_threshold: 0.095
deal_price: close
open_cost: 0.0005
close_cost: 0.0015
min_cost: 5
跑:
qrun workflow_config_lightgbm_Alpha158.yaml
跑完会在 mlruns/ 下面生成一次实验记录,里面包含 pred.pkl(模型预测)、port_analysis_1day.pkl(组合分析)和一个 report.html。这个 HTML 用 plotly 画了净值曲线、超额收益、滚动夏普、最大回撤等图,直接用浏览器打开看。
YAML 里 YAML anchor(&market / *market)是 Qlib 配置的常用技巧,避免 train/test/backtest 三处重复写股票池和时间段。改一处全局生效。
写自己的 Alpha 表达式
Qlib 的表达式语法是它的灵魂。任何 OHLCV 字段加 $ 前缀($close、$volume、$high 等),算子用类似 talib 的命名(Mean、Std、Ref、Rank、Corr、Cov、Sum、Min、Max、Abs、Log、Sign、Greater、Less、If)。
举几个例子:
| 表达式 | 含义 |
|---|---|
Mean($close, 5) | 5 日收盘均价 |
Ref($close, 1) | 昨日收盘价(lag 1) |
($close - Ref($close, 5)) / Ref($close, 5) | 5 日收益率 |
Std($close/Ref($close,1)-1, 20) | 20 日日收益率波动 |
Rank(Mean($volume, 5)/Mean($volume, 60)) | 短期/长期成交量比的横截面排名 |
Corr($close, $volume, 10) | 10 日量价相关 |
注意 Rank 是横截面排名,在某一天对所有股票排,其它算子默认是时序滚动。这是和 WorldQuant Alpha 表达式最大的差别(参见 WorldQuant Alpha 101 全解读)。
写一个自定义因子集,最简单的方式是继承 DataHandlerLP:
from qlib.data.dataset.handler import DataHandlerLP
from qlib.data.dataset.loader import QlibDataLoader
class MyHandler(DataHandlerLP):
def __init__(self, instruments="csi300",
start_time=None, end_time=None,
fit_start_time=None, fit_end_time=None, **kwargs):
feature_fields = [
"Mean($close, 5)/$close - 1",
"Mean($close, 20)/$close - 1",
"Std($close/Ref($close,1)-1, 20)",
"Corr($close, Log($volume+1), 10)",
]
feature_names = ["ma5_dev", "ma20_dev", "vol20", "pv_corr10"]
label_fields = ["Ref($close, -2)/Ref($close, -1) - 1"]
label_names = ["LABEL0"]
data_loader = {
"class": "QlibDataLoader",
"kwargs": {
"config": {
"feature": (feature_fields, feature_names),
"label": (label_fields, label_names),
},
},
}
super().__init__(
instruments=instruments,
start_time=start_time, end_time=end_time,
data_loader=data_loader,
fit_start_time=fit_start_time, fit_end_time=fit_end_time,
**kwargs,
)
四个因子就能跑出一个简易模型,用来验证想法很快。
回测与绩效分析:TopkDropout 与 IC/ICIR 怎么读
Qlib 默认的 TopkDropoutStrategy 是个简单但有效的多头策略。逻辑是:每天根据模型预测分数排序,持有前 K 名(topk),下一个交易日把分数掉到一定位次之外的 N 名扔掉(n_drop),然后从新的 top 区间补 N 只进来。
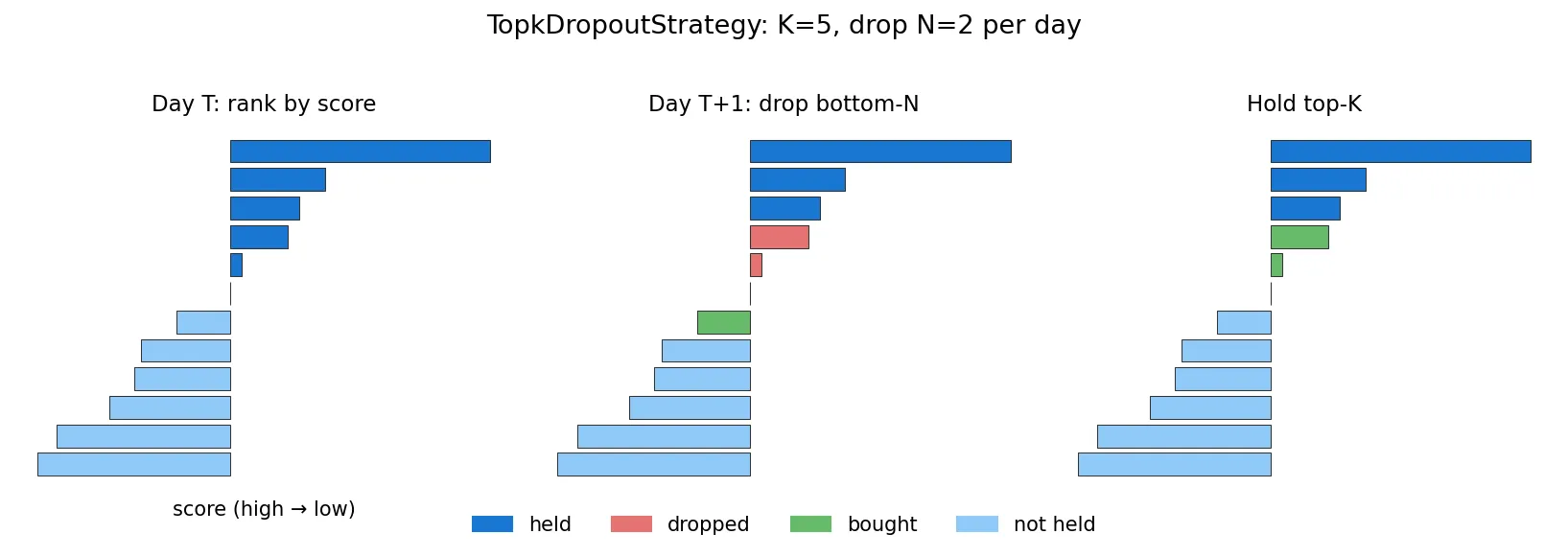
为什么不每天全量换仓?换手太高,交易成本会把 alpha 全吃掉。n_drop 控制换手率,K=50, n_drop=5 大约对应每日 10% 换手,比较常见的工业界设置。
回测产出的关键指标怎么看:
| 指标 | 含义 | 参考范围 |
|---|---|---|
| IC | 预测值与下期实际收益的 Pearson 相关 | A 股日频 0.02-0.08 算正常 |
| Rank IC | 改用秩相关,更鲁棒 | 通常比 IC 略高 |
| ICIR | IC 均值 / IC 标准差,衡量稳定性 | > 0.3 算不错 |
| 年化收益 | 组合年化总收益 | 10%-25% 区间常见 |
| 超额年化 | 减去基准(CSI300) | 正向才有意义 |
| 最大回撤 | 最差的累计跌幅 | A 股策略 -20% 到 -40% 都算正常 |
| 夏普比 | 收益 / 波动 | > 1 可上手,> 2 罕见 |
这里有个新手常踩的雷:看到 IC 0.05、年化 30%、夏普 2.5 就很激动,急着下结论。先检查几件事:测试段是不是在 train 范围之外(lookahead bias)?Alpha158 的 label 是 Ref($close,-2)/Ref($close,-1)-1(T+1 收盘到 T+2 收盘的收益),决策点是 T 日盘后,最早能成交是 T+1 收盘,如果你不小心把决策推到 T 日的盘中,就实际包含了未来信息(参见 回测中的常见陷阱)。Qlib 的默认配置是干净的,但自定义 label 时一定要数清楚 Ref 的偏移量。
常见报错与避坑清单
按出现频率排序,这些是 Qlib 教程里少见但实战必踩的坑:
1. FileNotFoundError: ... cn_data/calendars/day.txt 找不到
qlib.init 里的 provider_uri 路径写错了,或者用了 ~ 但当前 shell 不展开。改绝对路径解决。Windows 下 ~ 经常不展开。
2. ValueError: instruments csi300 not found
数据下载不全,或者 region 和 provider_uri 对不上。检查 ~/.qlib/qlib_data/cn_data/instruments/ 下有没有 csi300.txt,没有就重新跑一次 get_data。
3. LightGBM 训练时 Cannot allocate memory
Alpha158 在 csi300 全集上特征矩阵大概 (1.5M, 158),内存峰值 6-8GB。台式机够,云上小实例不够。要么换更大内存,要么把 instruments 缩到 csi100 或 start_time 推后几年。
4. MLP/GRU 模型训练 loss 不降
Qlib 内置的神经网络模型(如 qlib.contrib.model.pytorch_general_nn.GeneralPTNN)默认不对 Alpha158 做特征标准化,而 158 个因子量级差几个数量级。需要在 DataHandler 里加 processors 配置 RobustZScoreNorm 或 CSZScoreNorm。LightGBM 不需要这一步,所以教程多用 LightGBM 入门。
5. 数据更新到最近
官方 get_data 拉的数据通常滞后几个月。要更新到昨天,参考下面这套:
# 用 akshare 采集器拉 A 股增量到 csv
python scripts/data_collector/akshare/collector.py download_data \
--source_dir ~/qlib_raw/cn --region cn --delay 1
# 再 dump 成 .bin 列文件
python scripts/dump_bin.py dump_all \
--csv_path ~/qlib_raw/cn \
--qlib_dir ~/.qlib/qlib_data/cn_data \
--include_fields open,close,high,low,volume,factor
--factor 是复权因子列,缺这个 LightGBM 训出来的预测会被分红除权污染。第一次跑全量大概 1-2 小时,之后只补增量分钟级完成。
6. qrun 提示 mlflow.exceptions.MlflowException: Run ... not found
mlruns/ 目录被手动删过或权限问题。删掉残留的 mlruns/0/ 重新跑。
7. Windows 下中文路径
把数据放在 D:/qlib_data/,别放 D:/我的数据/。Qlib 的某些 C 扩展对非 ASCII 路径有 bug。
进阶方向:RL、滚动训练、RD-Agent
走完上面的入门流程后,Qlib 还有几个值得继续学的方向:
Rolling Training(滚动训练):现实里模型不能训一次用三年,市场风格会漂。Qlib 的 qlib.workflow.task.collect 和 RollingGen 提供了按月/季滚动重训的工具。
强化学习订单执行:qlib.rl 模块支持把订单切分成小单的 RL 策略,对接了 OPDS、PPO 等算法,论文复现代码在 examples/rl_order_execution/。
RD-Agent:微软 2024 年 7 月发布的 LLM 自动化因子挖掘工具,github.com/microsoft/RD-Agent,把 Qlib 当成执行环境,让 LLM 自动写新因子、跑实验、看结果、迭代。这是 Qlib 最近一年最受关注的方向,相关论文笔记可以看 AlphaAgent 解读 和 AlphaGPT 解读。
Point-in-Time 数据:财务数据有公告滞后,Qlib 的 PIT 数据库支持按公告日时间戳取数据,避免基本面回测的未来函数问题。
入门到这里基本够用了。如果按这条路径跑下来,Qlib 教程类博客里 90% 的内容你都已经覆盖,下一步真正能拉开差距的是两件事:在自己关心的股票池和时间段上写出第一批自定义因子并跑滚动训练验证稳定性,以及把 RD-Agent 接进来让 LLM 帮你穷举因子组合。这两块我会另开两篇细讲:[滚动训练 + akshare 增量更新流程]、[RD-Agent 用 Qlib 做因子挖掘实操],关注这个博客等更新。