配对交易(Pairs Trading)的核心逻辑很简单:找两只"走势应该同步"的股票,当它们的价差偏离历史常态时下注回归。做多价格偏低的那只,做空价格偏高的那只,等价差收敛后平仓获利。不赌大盘方向,赚的是两只股票之间的相对定价回归。
为什么是协整而不是相关性
新手做配对交易最常犯的错误:用相关性(correlation)来找配对。两只股票过去一年的相关性是 0.95,看起来非常适合做配对。问题是,高相关不等于价差会回归。
考虑两只同行业股票,过去一年都涨了 40%,相关性 0.95。但 A 每个月比 B 多涨 0.5%。到年底,A 累计比 B 多涨了 6%。相关性依然很高(两者同涨同跌),但价差在持续扩大,根本不回归。做配对交易等价差收敛的人会一直等下去。
相关性衡量的是"两个序列是否同向波动",协整(cointegration)衡量的是"两个序列的线性组合是否平稳"。平稳的意思是均值回归:价差偏离了,会被拉回来。
经典类比:酒鬼和他的狗。两者各自随机游走(非平稳),但绳子把它们绑在一起。酒鬼和狗的距离(价差)是平稳的,不会无限扩大。配对交易就是在赌"绳子"存在。
数学上:两个 I(1) 序列 \(X_t\) 和 \(Y_t\),如果存在常数 \(\beta\) 使得 \(Y_t - \beta X_t\) 是 I(0)(平稳的),则称 \(X\) 和 \(Y\) 协整。
协整检验:Engle-Granger 两步法
最常用的协整检验是 Engle-Granger 两步法:
第一步:用 OLS 回归 \(Y\) 对 \(X\),得到对冲比率 \(\hat{\beta}\) 和残差序列 \(e_t = Y_t - \hat{\beta} X_t\)。
第二步:对残差 \(e_t\) 做 ADF(Augmented Dickey-Fuller)检验。如果 ADF 的 p 值小于阈值(通常 0.05),拒绝"残差有单位根"的原假设,认为残差平稳,即两个序列协整。
用 yfinance 下载数据,完整代码如下:
import numpy as np
import yfinance as yf
from statsmodels.tsa.stattools import adfuller
from sklearn.linear_model import LinearRegression
# 下载数据
tickers = ["KO", "PEP"] # 可口可乐 vs 百事
data = yf.download(tickers, start="2023-01-01", end="2024-12-31")["Close"]
data = data.dropna()
X = data["KO"].values.reshape(-1, 1)
Y = data["PEP"].values
# 第一步:OLS 回归
reg = LinearRegression().fit(X, Y)
beta = reg.coef_[0]
intercept = reg.intercept_
spread = Y - beta * X.flatten() - intercept
print(f"对冲比率 beta = {beta:.4f}")
print(f"截距 = {intercept:.4f}")
# 第二步:ADF 检验
adf_result = adfuller(spread, autolag="AIC")
print(f"ADF 统计量: {adf_result[0]:.4f}")
print(f"p 值: {adf_result[1]:.4f}")
print(f"结论: {'协整' if adf_result[1] < 0.05 else '不协整'}")
以 KO/PEP 为例,典型输出类似:
对冲比率 beta = 2.9477
截距 = -3.8326
ADF 统计量: -3.9587
p 值: 0.0016
结论: 协整
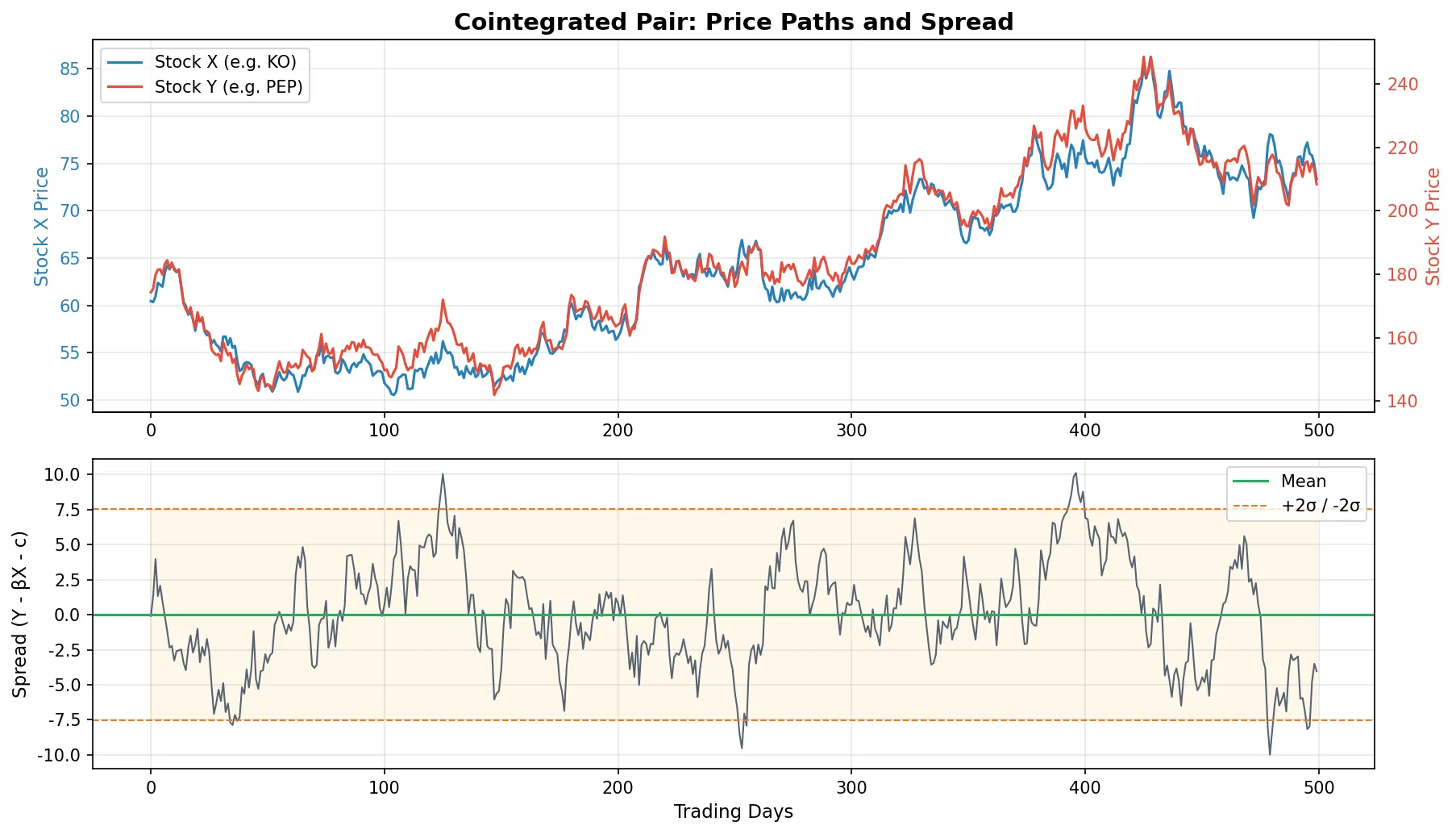
ADF p 值远小于 0.05,说明 KO 和 PEP 的价差是平稳的。对冲比率 β ≈ 2.95 意味着每做多 1 股 PEP 需要做空约 2.95 股 KO 来对冲。
几个注意事项:
样本选择:用 2-3 年的日线数据是常见选择。太短(半年)样本量不够,ADF 检验功效低;太长(10 年)可能跨越了 regime change,协整关系可能在早期成立但近期已经破裂。
配对候选:不要盲目遍历所有股票组合。先用行业逻辑筛选候选对(同行业、同供应链、同类 ETF),然后用协整检验验证。盲目搜索 5000 只股票的两两组合(1250 万对)会产生大量虚假协整(多重检验问题)。
Johansen 检验:如果你想同时检验三只或更多股票的协整关系,Engle-Granger 不够用,需要 Johansen 检验。它能找出多个协整向量,适合篮子交易(basket trading)。
价差构建
协整检验通过后,下一步是构建可交易的价差(spread)。
$$\text{spread}_t = Y_t - \beta X_t - c$$其中 \(\beta\) 是对冲比率(OLS 斜率),\(c\) 是截距。这个价差应该是平稳的、均值回归的。
滚动窗口 vs 全样本:上面的 \(\beta\) 用全样本回归得到,但协整关系不是一成不变的。对冲比率会缓慢漂移。实操中用滚动窗口(如 60 个交易日)动态更新 \(\beta\):
def rolling_hedge_ratio(Y, X, window=60):
"""滚动窗口计算对冲比率"""
betas = np.full(len(Y), np.nan)
for i in range(window, len(Y)):
reg = LinearRegression().fit(X[i-window:i].reshape(-1, 1), Y[i-window:i])
betas[i] = reg.coef_[0]
return betas
Z-score 标准化:把价差转换成标准分数,方便设阈值。
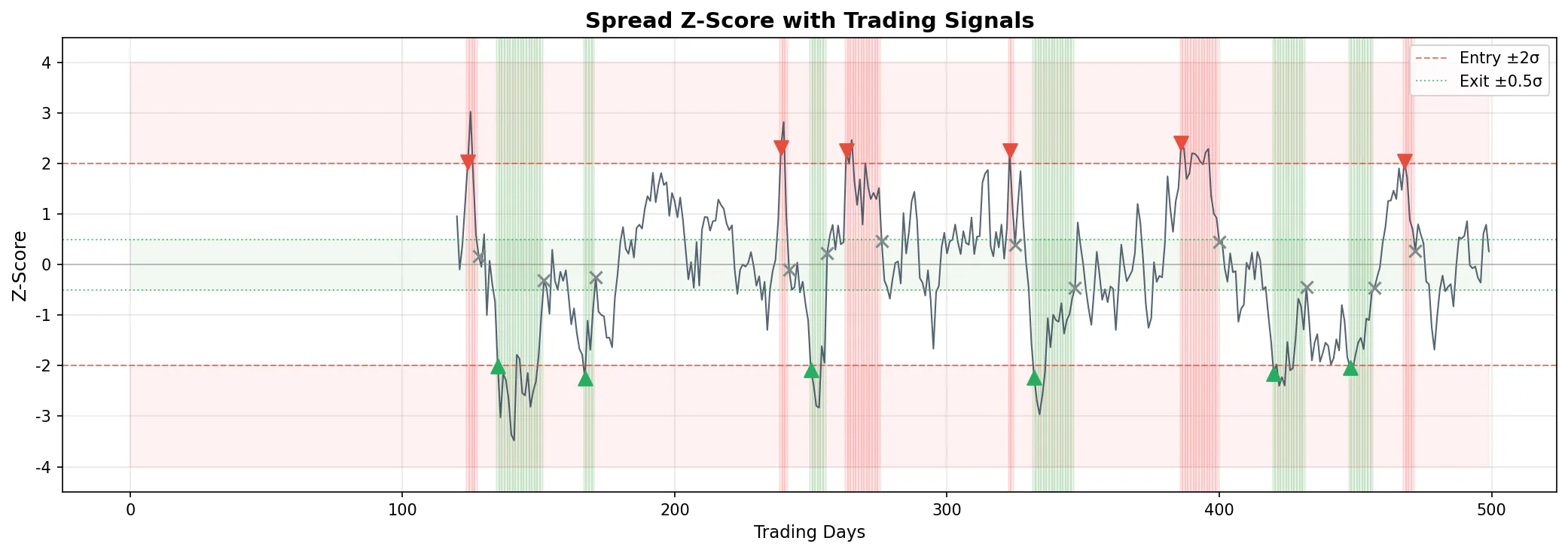
$$Z_t = \frac{\text{spread}_t - \overline{\text{spread}}}{\text{std}(\text{spread})}$$均值和标准差也用滚动窗口。Z-score 超过 2 表示价差偏离了 2 个标准差,是一个潜在的入场信号。
交易信号与回测
经典的均值回归信号:
| Z-score 条件 | 操作 |
|---|---|
| Z > +2 | 做空价差(做空 Y,做多 \(\beta\) 份 X) |
| Z < -2 | 做多价差(做多 Y,做空 \(\beta\) 份 X) |
| |Z| < 0.5 | 平仓(价差已回归) |
| |Z| > 4 | 止损(价差继续扩大,协整可能已破裂) |
完整的信号生成和简单回测:
import numpy as np
import yfinance as yf
from sklearn.linear_model import LinearRegression
# 数据准备
data = yf.download(["KO", "PEP"], start="2023-01-01", end="2024-12-31")["Close"].dropna()
Y = data["PEP"].values
X = data["KO"].values
# 滚动参数
lookback = 60
start = 2 * lookback # 前 2*lookback 天用于预热
# 计算滚动价差和 Z-score
spread = np.full(len(Y), np.nan)
z_score = np.full(len(Y), np.nan)
for i in range(lookback, len(Y)):
reg = LinearRegression().fit(X[i-lookback:i].reshape(-1, 1), Y[i-lookback:i])
beta = reg.coef_[0]
spread[i] = Y[i] - beta * X[i] - reg.intercept_
# Z-score 用价差自身的滚动均值和标准差
for i in range(start, len(Y)):
window = spread[i-lookback:i]
valid = window[~np.isnan(window)]
if len(valid) >= 20 and np.std(valid) > 0:
z_score[i] = (spread[i] - np.mean(valid)) / np.std(valid)
# 生成信号
position = np.zeros(len(Y)) # +1 = long spread, -1 = short spread
for i in range(start + 1, len(Y)):
if np.isnan(z_score[i]):
position[i] = position[i-1]
continue
if position[i-1] == 0:
if z_score[i] > 2:
position[i] = -1 # 做空价差
elif z_score[i] < -2:
position[i] = +1 # 做多价差
elif position[i-1] == 1: # 当前做多价差(Z<-2 时入场)
if abs(z_score[i]) < 0.5: # 价差回归,平仓
position[i] = 0
elif z_score[i] < -4: # 价差继续扩大,止损
position[i] = 0
else:
position[i] = 1
elif position[i-1] == -1: # 当前做空价差(Z>+2 时入场)
if abs(z_score[i]) < 0.5: # 价差回归,平仓
position[i] = 0
elif z_score[i] > 4: # 价差继续扩大,止损
position[i] = 0
else:
position[i] = -1
# 简单 P&L(价差的日变化 × 仓位)
spread_ret = np.diff(spread)
daily_pnl = position[start:-1] * spread_ret[start-1:]
daily_pnl = daily_pnl[~np.isnan(daily_pnl)]
cumulative_pnl = np.cumsum(daily_pnl)
n_trades = int(np.sum(np.abs(np.diff(position[start:])) > 0))
print(f"总 P&L: {cumulative_pnl[-1]:.2f}")
print(f"交易次数: {n_trades}")
print(f"日均 P&L: {np.mean(daily_pnl):.4f}")
print(f"夏普比率(年化): {np.mean(daily_pnl) / np.std(daily_pnl) * np.sqrt(252):.2f}")
用 KO/PEP 的 2023-2024 数据跑上面的代码,典型结果:
总 P&L: 46.07
交易次数: 24 (12 个来回)
日均 P&L: 0.1215
夏普比率(年化): 2.19
12 次来回交易,年化夏普 2.19,看起来不错。但要注意几点:策略只有 27% 的时间在持仓(价差大部分时间在 ±2σ 以内),没有扣交易成本,没有考虑两条腿的保证金占用。实际夏普会低不少。
这个回测非常简化,没有考虑交易成本、滑点和资金占用。实际表现会比回测差。
风险和局限
协整关系会破裂。 这是配对交易最大的风险。两只股票过去 3 年协整,不代表未来还协整。公司基本面变化(并购、业务转型、监管变更)可以永久打破协整关系。实操中需要持续监控:定期(如每月)重新做 ADF 检验,如果 p 值上升到 0.10 以上就考虑关闭该配对。
执行风险。 配对交易需要同时买一只卖一只。两条腿如果不能同时成交,中间的延迟就是方向性暴露。流动性差的股票尤其危险:你可能只成交了一条腿,另一条腿的价格已经动了。
资金效率。 做多一只做空一只,两条腿都占用保证金或资金。和单边策略比,配对交易的资金利用率更低。如果你能用凯利公式算出每个配对的最优仓位,可以在多个配对之间分配资金。
收敛速度不确定。 价差偏离了 2 个标准差,可能明天就回来,也可能两个月后才回来。持仓期间资金被锁定,机会成本是隐性亏损。
回测中的过拟合风险。 配对交易的回测特别容易过拟合。你从 5000 只股票中筛选出通过协整检验的配对,本质上就是在做数据挖掘。解决方案是严格的样本外验证:用前 2 年筛选配对,用第 3 年验证,只在样本外也通过协整检验的配对上交易。
配对交易的夏普比率一般在 1.0-2.0 之间,不是特别高,但胜在稳定和市场中性。