同一个策略,仓位 10% 和仓位 50%,长期下来可以是稳定盈利和账户归零的区别。选股、择时、因子设计都是在回答"买什么",仓位管理回答的是"买多少"。凯利公式(Kelly Criterion)是这个问题的数学最优解。
经典凯利公式
凯利公式起源于 1956 年贝尔实验室的 John Kelly。原始场景是一个简单的二元赌博:每局胜率 \(p\),败率 \(q = 1-p\),赔率 \(b\)(赢了拿回本金加上 \(b\) 倍本金,输了赔光下注金额)。你手里有固定本金,每局押多大比例?
凯利的答案:
$$f^* = \frac{bp - q}{b} = \frac{bp - (1-p)}{b}$$其中 \(f^*\) 是最优下注比例(占总资金的百分比)。
数值例子:胜率 55%,赔率 1:1(\(b=1\))。
$$f^* = \frac{1 \times 0.55 - 0.45}{1} = 0.10$$最优下注比例是 10%。直觉上合理:你有微弱优势,但不应该重仓。
凯利最大化的不是单局期望收益,而是对数资金增长率。对数增长率是几何增长的核心指标。算术期望可以很高,但如果某一局亏光了,几何增长率直接变成负无穷。凯利公式找的是让 \(E[\ln(W)]\) 最大的 \(f\),其中 \(W\) 是每局后的财富。
推导过程:每局后资金为 \(W_{n+1} = W_n(1 + f \cdot X)\),\(X\) 取 \(+b\)(概率 \(p\))或 \(-1\)(概率 \(q\))。对数增长率的期望:
$$G(f) = p \ln(1 + bf) + q \ln(1 - f)$$对 \(f\) 求导令其为零,解出来就是上面的公式。
凯利公式有一个重要性质:\(f^*\) 只有在期望值为正时才大于零。如果 \(bp < q\)(负期望),公式给出负值,意味着不应该下注(或者反向下注)。这和直觉一致:没有优势就不玩。
连续情况:收益率分布的凯利
实际交易中收益不是"要么赚 b 要么赔光"这么简单。标的的收益率是连续分布的。假设策略的对数收益率近似正态分布,均值 \(\mu\),标准差 \(\sigma\),无风险利率 \(r\)。连续版本的凯利公式:
$$f^* = \frac{\mu - r}{\sigma^2}$$这个公式的直觉:\(\mu - r\) 是超额收益(你的优势),\(\sigma^2\) 是风险(方差)。优势越大仓位越高,风险越大仓位越低。
和夏普比率的关系很直接。夏普比率 \(SR = \frac{\mu - r}{\sigma}\),所以:
$$f^* = \frac{SR}{\sigma}$$夏普比率 1.0、年化波动率 20% 的策略,凯利最优杠杆是 \(1.0 / 0.20 = 5\) 倍。夏普 0.5、波动率 30% 的策略,凯利杠杆是 \(0.5 / 0.30 \approx 1.67\) 倍。
这揭示了一个重要的现实:很多量化策略的凯利最优杠杆远高于直觉。一个年化收益 15%、波动率 10% 的策略(\(\mu - r = 0.10\),假设 \(r = 5\%\)),凯利杠杆是 \(0.10 / 0.01 = 10\) 倍。用 10 倍杠杆跑,理论上长期增长最快,但过程会非常痛苦。
分数凯利:实操的关键
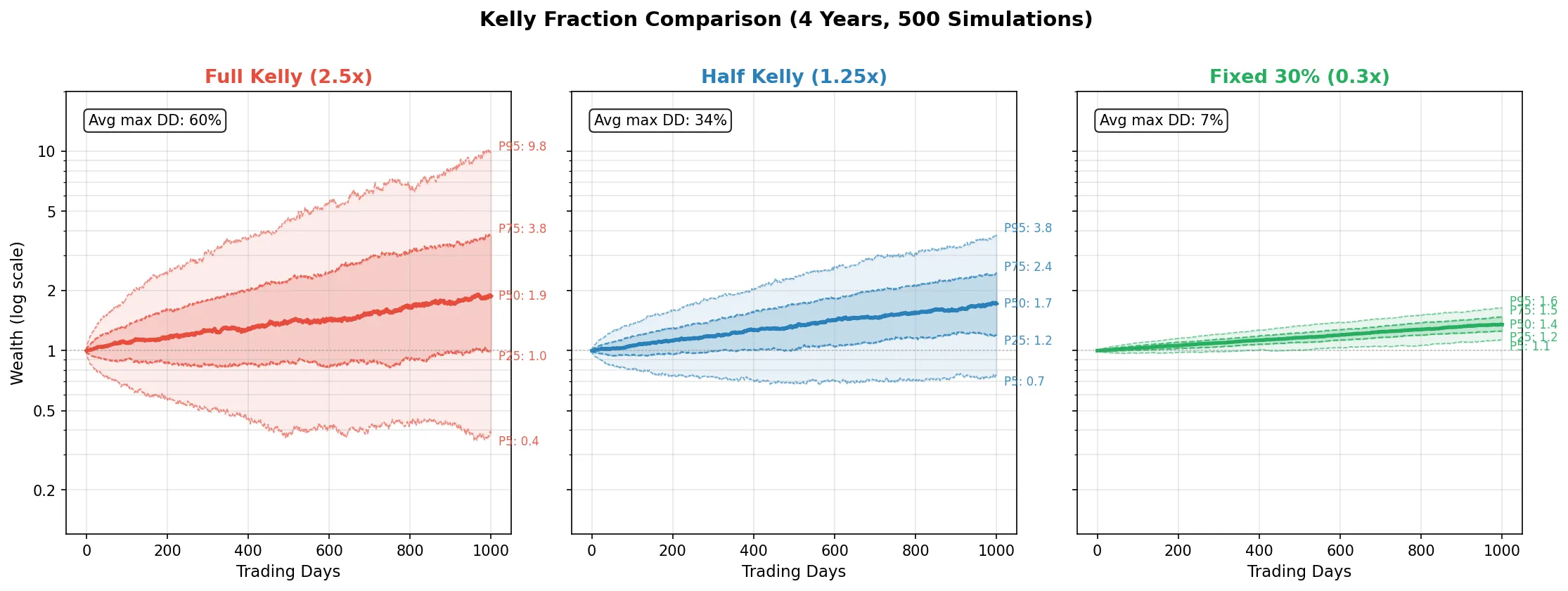
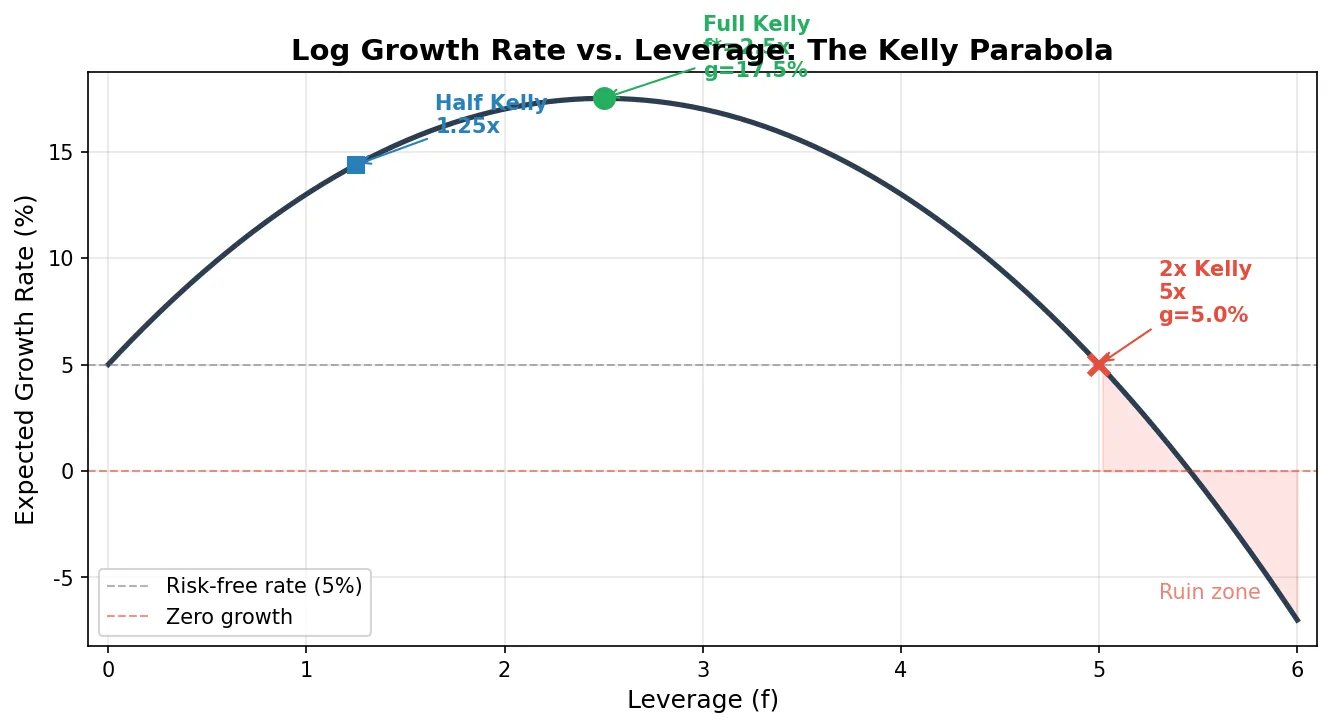
直接使用公式算出的 \(f^*\) 做仓位叫全凯利(Full Kelly)。上一节的例子里,\(f^* = 2.5\) 就意味着全凯利要求你用 2.5 倍杠杆。全凯利是理论增长率最大化的点,但实操中问题很大:
- 回撤太深。全凯利的理论最大回撤可以接近 100%。模拟 1000 次赌局,全凯利在中途经常出现 50-80% 的回撤。
- 参数估计误差被放大。你用历史数据估算 \(\mu\) 和 \(\sigma\),但这些只是估计值。如果真实 \(\mu\) 比你估计的低,全凯利就变成了 over-bet,后果是灾难性的。Over-bet 比 under-bet 危险得多:under-bet 只是增长慢一些,over-bet 的长期增长率是负的。
所以实操中几乎所有人用分数凯利(Fractional Kelly):不直接用 \(f^*\),而是乘一个小于 1 的系数。\(f^*/2\) 叫半凯利(Half Kelly),\(f^*/3\) 叫三分之一凯利。如果全凯利是 2.5 倍杠杆,半凯利就是 1.25 倍,三分之一凯利就是 0.83 倍。
半凯利的性质很好:
- 期望增长率是全凯利的 75%(只牺牲了 25% 的增长速度)
- 最大回撤大约减半
- 对参数估计误差更鲁棒
下面用 Python 模拟对比全凯利、半凯利、固定仓位的净值曲线:
import numpy as np
def simulate_kelly(mu, sigma, r, fraction, n_days=1000, n_sims=500):
"""
模拟不同凯利分数下的净值路径
mu: 策略年化收益率
sigma: 策略年化波动率
fraction: 凯利分数 (1.0=全凯利, 0.5=半凯利)
"""
dt = 1 / 252 # 日频
kelly_full = (mu - r) / sigma**2
f = kelly_full * fraction
daily_mu = mu * dt
daily_sigma = sigma * np.sqrt(dt)
np.random.seed(42)
returns = np.random.normal(daily_mu, daily_sigma, (n_sims, n_days))
# 每日按凯利比例配置,剩余放无风险
wealth = np.ones((n_sims, n_days + 1))
for t in range(n_days):
portfolio_return = f * returns[:, t] + (1 - f) * r * dt
wealth[:, t + 1] = wealth[:, t] * (1 + portfolio_return)
return wealth
mu, sigma, r = 0.15, 0.20, 0.05
wealth_full = simulate_kelly(mu, sigma, r, fraction=1.0)
wealth_half = simulate_kelly(mu, sigma, r, fraction=0.5)
wealth_fixed = simulate_kelly(mu, sigma, r, fraction=0.3) # 固定30%仓位
# 统计
for name, w in [("全凯利", wealth_full), ("半凯利", wealth_half), ("固定30%", wealth_fixed)]:
final = w[:, -1]
median_return = np.median(final)
max_dd = np.min(w / np.maximum.accumulate(w, axis=1), axis=1)
avg_max_dd = np.mean(1 - max_dd)
print(f"{name}: 中位终值={median_return:.2f}, 平均最大回撤={avg_max_dd:.1%}")
参数设定:年化收益 \(\mu=15\%\),波动率 \(\sigma=20\%\),无风险利率 \(r=5\%\)。先算全凯利最优杠杆:\(f^* = (0.15 - 0.05) / 0.20^2 = 2.5\),意味着公式建议你把资金的 250% 投入策略(即 2.5 倍杠杆)。全凯利(fraction=1.0)就是直接用这个 2.5 倍;半凯利(fraction=0.5)取一半,即 1.25 倍;固定 30% 是不管公式怎么算,始终只投入 30% 资金。500 条路径,每条 1000 个交易日(约 4 年)。运行结果:
| 杠杆 | 中位终值 | 均值终值 | 平均最大回撤 | 95 分位最大回撤 | |
|---|---|---|---|---|---|
| 全凯利 | 2.50x | 1.88 | 3.13 | 60.3% | 81.9% |
| 半凯利 | 1.25x | 1.72 | 1.96 | 34.5% | 52.4% |
| 固定 30% | 0.30x | 1.54 | 1.62 | 20.9% | 32.9% |
结论很清晰:全凯利 2.5 倍杠杆下中位终值最高(1.88 vs 1.72),但代价是 60% 的平均最大回撤,95 分位更是达到 82%。半凯利只用 1.25 倍杠杆,终值只低了 8%,回撤几乎减半。固定 30% 仓位最保守,回撤只有 21%,适合风险承受力低的策略。注意均值终值(3.13)远高于中位数(1.88),说明全凯利的分布是严重右偏的:少数路径暴赚拉高了均值,但大多数路径的表现不如均值暗示的那么好。
多资产凯利
单资产凯利只需要一个比率。多资产的情况需要协方差矩阵。假设你有 \(n\) 个资产,收益率向量 \(\boldsymbol{\mu}\),协方差矩阵 \(\boldsymbol{\Sigma}\),无风险利率 \(r\)。多资产凯利的最优权重向量:
$$\mathbf{f}^* = \boldsymbol{\Sigma}^{-1} (\boldsymbol{\mu} - r \cdot \mathbf{1})$$这个公式和均值方差优化(Markowitz)有直接关系。Markowitz 的切线组合(最大夏普比率组合)的权重正比于 \(\boldsymbol{\Sigma}^{-1}(\boldsymbol{\mu} - r \cdot \mathbf{1})\),但要归一化到目标风险水平。凯利组合就是切线组合不做归一化的版本,相当于"用多少杠杆就用多少杠杆"。
实操中不会直接用这个公式,因为 \(\boldsymbol{\Sigma}^{-1}\) 在高维度下极不稳定(条件数大,小扰动导致权重剧烈变化)。常见做法:
- 用 shrinkage estimator(如 Ledoit-Wolf)修正协方差矩阵
- 在权重上加约束(如单资产权重不超过 20%)
- 乘以分数凯利(如 1/3)来降低整体杠杆
如果你在做因子组合的仓位分配,多资产凯利提供了一个理论框架:每个因子的权重应该正比于它的超额收益除以它对组合方差的贡献。
import numpy as np
def multi_asset_kelly(mu, cov, r, fraction=0.5):
"""
多资产凯利权重
mu: (n,) 各资产预期年化收益率
cov: (n, n) 收益率协方差矩阵
r: 无风险利率
fraction: 凯利分数
"""
excess = mu - r
cov_inv = np.linalg.inv(cov)
kelly_weights = cov_inv @ excess * fraction
return kelly_weights
# 示例:3个资产
mu = np.array([0.12, 0.08, 0.15]) # 年化收益
sigma = np.array([0.20, 0.15, 0.25]) # 年化波动率
corr = np.array([
[1.0, 0.3, 0.5],
[0.3, 1.0, 0.2],
[0.5, 0.2, 1.0]
])
cov = np.outer(sigma, sigma) * corr
r = 0.05
weights = multi_asset_kelly(mu, cov, r, fraction=0.5)
print("半凯利权重:", np.round(weights, 3))
print("总杠杆:", round(np.sum(np.abs(weights)), 2))
输出:
半凯利权重: [0.441 0.294 0.588]
总杠杆: 1.32
资产 3(超额收益 10%,波动率 25%)获得最高权重 0.588,尽管它波动率最大,但超额收益也最高。资产 2(超额收益 3%,波动率 15%)权重最低。总杠杆 1.32 倍,比单资产凯利温和得多,因为资产间的相关性分散了风险(协方差矩阵求逆隐式地考虑了分散化效应)。
实操注意事项
参数估计误差是最大敌人。 凯利公式假设你知道真实的 \(\mu\) 和 \(\sigma\)。现实中你只有样本估计。\(\mu\) 的估计尤其不靠谱:250 个交易日的样本,\(\mu\) 的标准误差约等于 \(\sigma / \sqrt{250} \approx \sigma / 16\)。年化波动率 20% 的策略,\(\mu\) 的标准误差就是 1.25%。如果你估计的 \(\mu = 15\%\),真实值可能在 12-18% 之间。代入凯利公式,最优仓位可以差一倍。
这和回测陷阱直接相关。如果你在回测中过拟合了参数,\(\mu\) 被高估,凯利公式就会给出过高的仓位,实盘直接被打爆。
永远不要超过凯利仓位。 凯利仓位是增长率为零的边界:在全凯利时增长率最大,超过全凯利增长率开始下降,超过 2 倍凯利增长率变成负数(长期亏钱)。Under-bet 只是增长慢一些,over-bet 到一定程度后长期必亏。这是不对称的。
交易成本要从收益里扣。 凯利公式假设无摩擦。如果策略需要频繁调仓,交易成本(佣金、滑点、市场冲击)会吃掉一部分 \(\mu\)。用 \(\mu_{\text{net}} = \mu - \text{交易成本}\) 代入凯利,仓位会变小。这个调整在高频策略里尤其重要。
做空波动率时特别危险。 波动率交易策略里提到过,卖出波动率的收益分布是负偏的(大多数时候小赚,偶尔巨亏)。凯利公式在正态假设下工作最好,对负偏分布会系统性高估最优仓位。卖 VIX 期货的策略,凯利仓位按正态算是一回事,按真实的肥尾分布算又是另一回事。这也是 2018 年 2 月做空波动率基金爆仓的底层原因之一。
凯利是上限,不是目标。 实操中大多数量化基金用 1/4 到 1/2 凯利。牺牲一部分增长速度换取回撤可控和参数鲁棒性。如果你不确定用多少,半凯利是一个合理的起点。