一只股票涨了 20%,这 20% 里有多少是因为大盘整体在涨,多少是因为它是小盘股,多少是因为它便宜?Fama-French 因子模型就是用来回答这个问题的工具。它把股票收益拆解成几个可解释的"因子",是量化选股的基础框架之一。这篇文章从最基础的 CAPM 讲起,一步步推进到三因子和五因子模型,最后用 Python 跑一遍因子回归。
CAPM:一个因子的世界
在 Fama-French 之前,金融学用 CAPM(资本资产定价模型) 解释股票收益。CAPM 的核心公式:
$$ E(R_i) = R_f + \beta_i (R_m - R_f) $$翻译成人话:一只股票的预期收益 = 无风险利率 + 这只股票对市场的敏感度(β)× 市场风险溢价。
β 大于 1 的股票比大盘波动更剧烈,承担了更多风险,所以预期收益更高。β 小于 1 的反之。CAPM 的世界观很简洁:股票收益的差异只由一个东西决定,就是它对整体市场的暴露程度。
问题出在哪?实际数据不买账。
1981 年 Banz 发现,小市值股票的长期收益率显著高于大市值股票,超出 CAPM 预测的部分用 β 解释不了。1992 年 Fama 和 French 又发现,高账面市值比(B/M)的股票(也就是市场觉得"便宜"的股票)长期跑赢低 B/M 的"贵"股票。这两个现象被称为规模溢价和价值溢价,是 CAPM 的两大"异象"。
一个因子解释不了的东西,那就加因子。
三因子模型:规模和价值
1993 年,Fama 和 French 在 CAPM 的基础上加了两个因子,提出三因子模型:
$$ R_i - R_f = \alpha_i + \beta_1 (R_m - R_f) + \beta_2 \cdot \text{SMB} + \beta_3 \cdot \text{HML} + \varepsilon_i $$三个因子分别是:
MKT(市场因子),就是 CAPM 里的 \(R_m - R_f\)。大盘涨 1%,如果你的 \(\beta_1 = 1.2\),这个因子贡献 1.2% 的收益。
SMB(Small Minus Big,规模因子)。把所有股票按市值分成两组,小盘股组合的收益减去大盘股组合的收益。如果一只股票的 \(\beta_2\) 是正的,说明它的表现和小盘股同步,吃到了规模溢价。
HML(High Minus Low,价值因子)。把所有股票按账面市值比(B/M)分成两组,高 B/M(便宜)股票的收益减去低 B/M(贵)股票的收益。\(\beta_3\) 为正说明这只股票有价值股特征。
公式左边的 \(\alpha_i\) 是关键:它代表三个因子都解释不了的"超额收益"。如果一个基金经理的 α 显著为正,说明他确实有选股能力,赚的不只是承担市场、规模、价值三种风险带来的补偿。反过来说,很多看上去收益不错的基金,拆开一看 α 接近零,收益全是因子暴露带来的,换个 ETF 组合就能近似复制。
因子怎么构造
Fama 和 French 的原始构造方法:每年 6 月底,把所有股票按市值中位数分成大(Big)和小(Small)两组;同时按账面市值比的 30%/70% 分位数分成高(High)、中(Medium)、低(Low)三组。2 × 3 = 6 个组合。
- SMB = (三个小盘组合的平均收益)-(三个大盘组合的平均收益)
- HML = (两个高 B/M 组合的平均收益)-(两个低 B/M 组合的平均收益)
这种做多一边、做空另一边的构造方式叫多空对冲组合(long-short portfolio)。因子收益代表的是一种风格溢价,和市场整体涨跌无关。
五因子模型:盈利和投资
三因子模型解释了规模和价值效应,但还有些"异象"它搞不定。两个盈利能力差不多、市值也差不多的股票,为什么长期收益率差很多?Novy-Marx 在 2013 年发现盈利能力(gross profitability)可以预测股票收益。Fama 和 French 在 2015 年的论文里把盈利和投资两个维度加进来,扩展成五因子模型:
$$ R_i - R_f = \alpha_i + \beta_1 (R_m - R_f) + \beta_2 \cdot \text{SMB} + \beta_3 \cdot \text{HML} + \beta_4 \cdot \text{RMW} + \beta_5 \cdot \text{CMA} + \varepsilon_i $$新增的两个因子:
RMW(Robust Minus Weak,盈利因子)。盈利能力强(高营业利润率)的公司组合收益减去盈利能力弱的公司组合收益。直觉上好理解:赚钱能力强的公司,股票长期表现更好。
CMA(Conservative Minus Aggressive,投资因子)。投资保守(资产增长率低)的公司收益减去投资激进(大量扩张)的公司收益。听上去反直觉,但数据显示:疯狂扩张的公司往往过度投资,回报率下降,股价长期跑输那些稳健经营的公司。
五因子模型有一个有趣的副作用:加了 RMW 和 CMA 之后,HML(价值因子)的解释力明显变弱了。Fama 和 French 自己也在论文里承认,五因子模型中 HML 几乎是多余的,因为价值效应可以被盈利和投资两个因子大部分解释掉。这引发了学术界不小的争论:价值投资到底是一个独立的风险溢价,还只是盈利能力和投资风格的副产品?
Python 因子回归实战
理论讲完,下面用 Python 跑一遍。我们模拟一只"小盘价值基金"的月度收益,然后分别用三因子和五因子模型做回归,看各因子的系数和 α。
实际操作中,因子数据可以从 Kenneth French 的 Data Library 免费下载。这里为了代码自包含,用合成数据模拟。
import numpy as np
from numpy.linalg import lstsq
def run_factor_regression():
np.random.seed(42)
n = 240 # 20 years of monthly data
# Simulate factor returns (monthly)
mkt = np.random.normal(0.007, 0.045, n)
smb = np.random.normal(0.002, 0.032, n)
hml = np.random.normal(0.003, 0.028, n)
rmw = np.random.normal(0.0025, 0.022, n)
cma = np.random.normal(0.002, 0.020, n)
# Simulate fund returns: small-cap value fund
# True betas: MKT=1.05, SMB=0.45, HML=0.38, RMW=0.18, CMA=0.12
# True alpha: 0.001 (0.1% per month)
alpha_true = 0.001
fund = (alpha_true + 1.05 * mkt + 0.45 * smb + 0.38 * hml
+ 0.18 * rmw + 0.12 * cma + np.random.normal(0, 0.012, n))
# --- Three-factor regression ---
X3 = np.column_stack([np.ones(n), mkt, smb, hml])
beta3, residuals3, _, _ = lstsq(X3, fund, rcond=None)
pred3 = X3 @ beta3
ss_res3 = np.sum((fund - pred3) ** 2)
ss_tot = np.sum((fund - np.mean(fund)) ** 2)
r2_3 = 1 - ss_res3 / ss_tot
# Standard errors
mse3 = ss_res3 / (n - 4)
se3 = np.sqrt(np.diag(mse3 * np.linalg.inv(X3.T @ X3)))
t3 = beta3 / se3
print("=== Three-Factor Model ===")
print(f" Alpha: {beta3[0]*100:.3f}% /month (t={t3[0]:.2f})")
print(f" MKT: {beta3[1]:.3f} (t={t3[1]:.2f})")
print(f" SMB: {beta3[2]:.3f} (t={t3[2]:.2f})")
print(f" HML: {beta3[3]:.3f} (t={t3[3]:.2f})")
print(f" R²: {r2_3:.4f}")
# --- Five-factor regression ---
X5 = np.column_stack([np.ones(n), mkt, smb, hml, rmw, cma])
beta5, _, _, _ = lstsq(X5, fund, rcond=None)
pred5 = X5 @ beta5
ss_res5 = np.sum((fund - pred5) ** 2)
r2_5 = 1 - ss_res5 / ss_tot
mse5 = ss_res5 / (n - 6)
se5 = np.sqrt(np.diag(mse5 * np.linalg.inv(X5.T @ X5)))
t5 = beta5 / se5
print("\n=== Five-Factor Model ===")
print(f" Alpha: {beta5[0]*100:.3f}% /month (t={t5[0]:.2f})")
print(f" MKT: {beta5[1]:.3f} (t={t5[1]:.2f})")
print(f" SMB: {beta5[2]:.3f} (t={t5[2]:.2f})")
print(f" HML: {beta5[3]:.3f} (t={t5[3]:.2f})")
print(f" RMW: {beta5[4]:.3f} (t={t5[4]:.2f})")
print(f" CMA: {beta5[5]:.3f} (t={t5[5]:.2f})")
print(f" R²: {r2_5:.4f}")
print(f"\n R² improvement: {r2_3:.4f} -> {r2_5:.4f} (+{(r2_5-r2_3)*100:.2f}%)")
run_factor_regression()
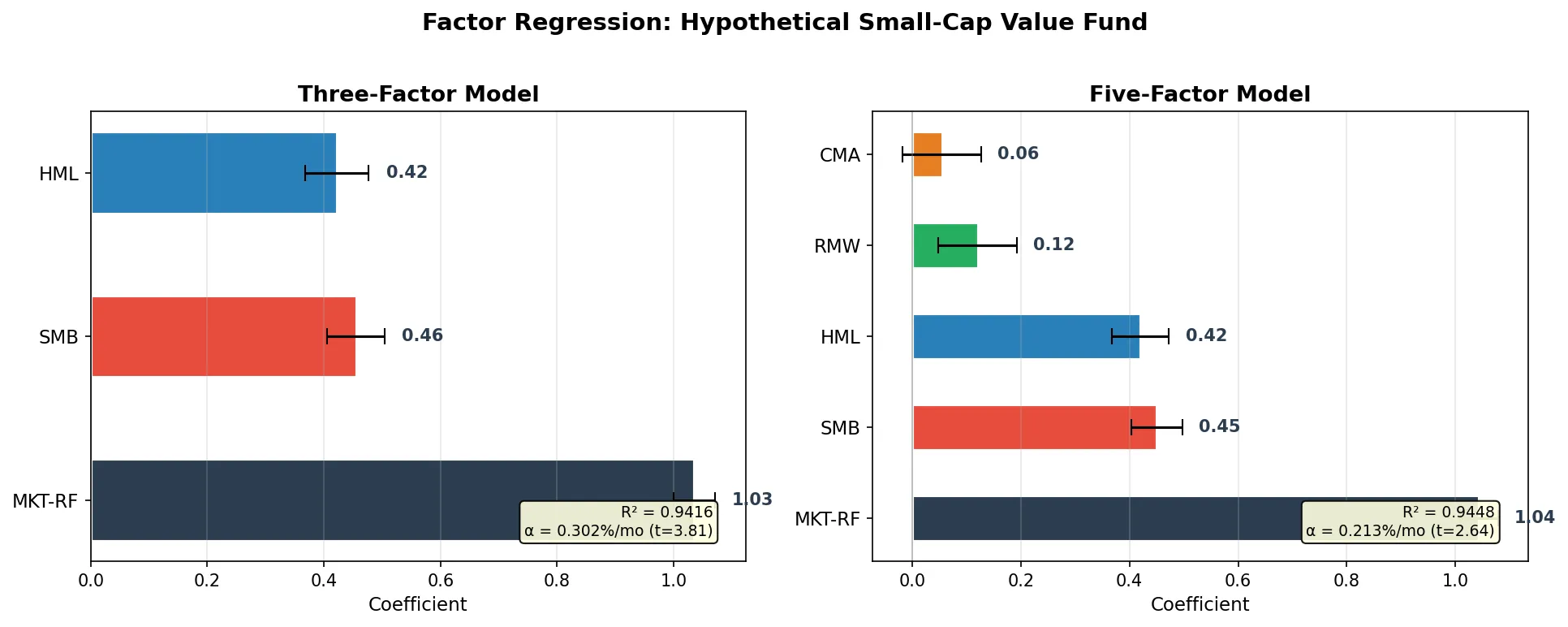
运行结果:
=== Three-Factor Model ===
Alpha: 0.302% /month (t=3.81)
MKT: 1.035 (t=57.98)
SMB: 0.455 (t=18.49)
HML: 0.422 (t=15.20)
R²: 0.9416
=== Five-Factor Model ===
Alpha: 0.213% /month (t=2.64)
MKT: 1.043 (t=59.28)
SMB: 0.450 (t=18.67)
HML: 0.420 (t=15.47)
RMW: 0.121 (t=3.27)
CMA: 0.055 (t=1.49)
R²: 0.9448
R² improvement: 0.9416 -> 0.9448 (+0.32%)
几个值得注意的结果:
MKT 系数 1.04,接近我们设定的真实值 1.05。t 值接近 60,极其显著。这只"基金"基本跟着大盘走。
SMB 系数 0.45,显著为正,说明这只基金确实偏小盘。如果你买了一只号称"大盘蓝筹"的基金,跑回归发现 SMB 显著为正,那基金经理实际上是在买小盘股,和宣传不符。
三因子的 α 是 0.302%/月,t 值 3.81,统计上显著。换到五因子模型后 α 降到 0.213%,t 值 2.64。原来三因子里"解释不了"的超额收益,有一部分其实是 RMW 和 CMA 因子的暴露。这就是因子模型的核心用途:剥掉因子暴露后,看真正的 α 还剩多少。
R² 从 0.9416 升到 0.9448。五因子比三因子多解释了 0.32% 的收益方差。提升不大,但 RMW 的 t 值 3.27 是显著的,说明盈利因子确实有独立的解释力。CMA 的 t 值 1.49 不显著,在这组数据里投资因子的效果偏弱。
因子模型的局限
因子模型是量化选股的基础框架,但不是万能的。
因子溢价会消失。小盘股溢价是三因子模型的核心卖点之一,但 1980 年代之后美股小盘股溢价大幅衰减,有些年份甚至为负。一种解释是:学术论文发表后大量资金涌入小盘股策略,溢价被套利掉了。因子拥挤是所有因子策略面临的长期威胁。
换个市场可能不灵。Fama-French 因子是在美股上发现的。搬到 A 股,规模效应(小盘股跑赢)依然很强,但价值效应(低估值跑赢)长期失效。A 股的"便宜"股票很多是基本面恶化的垃圾股,买入持有不但不赚钱还会亏。直接照搬美股因子模型到其他市场是危险的。
数据挖掘的重灾区。学术界已经"发现"了几百个所谓的因子(有人统计超过 400 个)。很多因子只在特定的时间段和特定的市场里有效,换个样本就消失了。Harvey, Liu & Zhu (2016) 的论文指出,用传统的 t > 2 标准,大量"显著"的因子其实是多重检验下的统计幻觉。
线性假设。因子模型假设收益和因子之间是线性关系。现实中,因子的效果可能是非线性的:小盘股溢价可能集中在最小的 10% 股票上,而不是"越小越好"的线性递增。
因子模型和量化选股
因子模型不只是一个分析工具,它是量化选股策略的理论地基。
最直接的应用:因子选股。如果你相信价值因子长期有效,就系统性地买入高 B/M 的股票、卖出低 B/M 的股票。如果你同时相信多个因子,就把它们组合起来,构建多因子评分模型。A 股量化私募大量使用的"多因子模型",底层逻辑就是这个。
因子归因。基金经理说自己年化 25%,因子模型可以告诉你:其中 18% 是市场涨的,4% 是小盘股溢价,2% 是价值溢价,真正的 α 只有 1%。你愿意为 1% 的 α 付 2% 的管理费吗?这就是因子归因的实际价值。
因子中性。有些策略不想承担任何因子风险,只赚纯 α。方法是在构建组合时,约束对每个因子的暴露为零。比如做多一组股票的同时,做空等量的、因子暴露相反的股票,让组合的 SMB、HML 等系数都接近零。剩下的收益就是和因子无关的纯选股能力。
因子模型的数学不复杂,本质就是多元线性回归。真正难的是:选哪些因子,怎么处理因子之间的相关性,因子权重怎么动态调整,以及怎么避免在历史数据上过度拟合。