公式化因子挖掘做到一定规模会撞上一堵墙:库里已经有几十个因子,新挖的候选 IC 不算差,但跟现有因子相关性总是超过阈值,admit 不进去。AlphaGPT、AlphaForge、AlphaAgent、QuantFactor REINFORCE 都在解决"怎么生成更多候选",对"库越大越难加新货"的处理仍有限。
FactorMiner(A Self-Evolving Agent with Skills and Experience Memory for Financial Alpha Discovery,2026/02,arXiv 2602.14670)的核心思路:把因子挖掘流程封装成一个 agent skill,并维护一个 experience memory 记录"哪些方向已经撞墙、哪些模板还能复用",让 agent 每轮挖掘都从过去的成功和失败里取先验。CSI500 上 top-40 因子的 IC 达到 8.25%,ICIR 0.77,对比 AlphaAgent 的 5.90%/0.46 是约 40% 的相对提升。
问题背景
论文把因子挖掘的核心痛点叫 “Correlation Red Sea”。形式化定义:每挖出一个新因子 \(\alpha\),要求它和库 \(\mathcal{L}\) 里所有已有因子的最大相关性低于阈值 \(\theta\):
$$ \mathcal{P}_{\text{orth}} = \\{ \alpha \in \mathcal{P} : \max_{\beta \in \mathcal{L}} |\rho(\alpha, \beta)| < \theta \\} $$随着 \(\mathcal{L}\) 变大,\(\mathcal{P}_{\text{orth}}\) 这个可行区域缩得极快。GP 和 RL 这类标准搜索方法对此没有应对机制:它们不记得哪些区域已经探过、哪些方向反复撞墙,越往后越在原地打转。
更头疼的是这类方法把每个因子当独立优化问题处理,只看 IC/ICIR 这种个体指标,不考虑新因子和已有库的协同。即使个体指标很好,加进库里冗余。
方法
FactorMiner 的解法有两层:把领域知识封装成 agent 可复用的 skill,把过去的探索经验沉淀成 memory,再用一个 retrieve/generate/evaluate/distill 的循环把两者串起来。
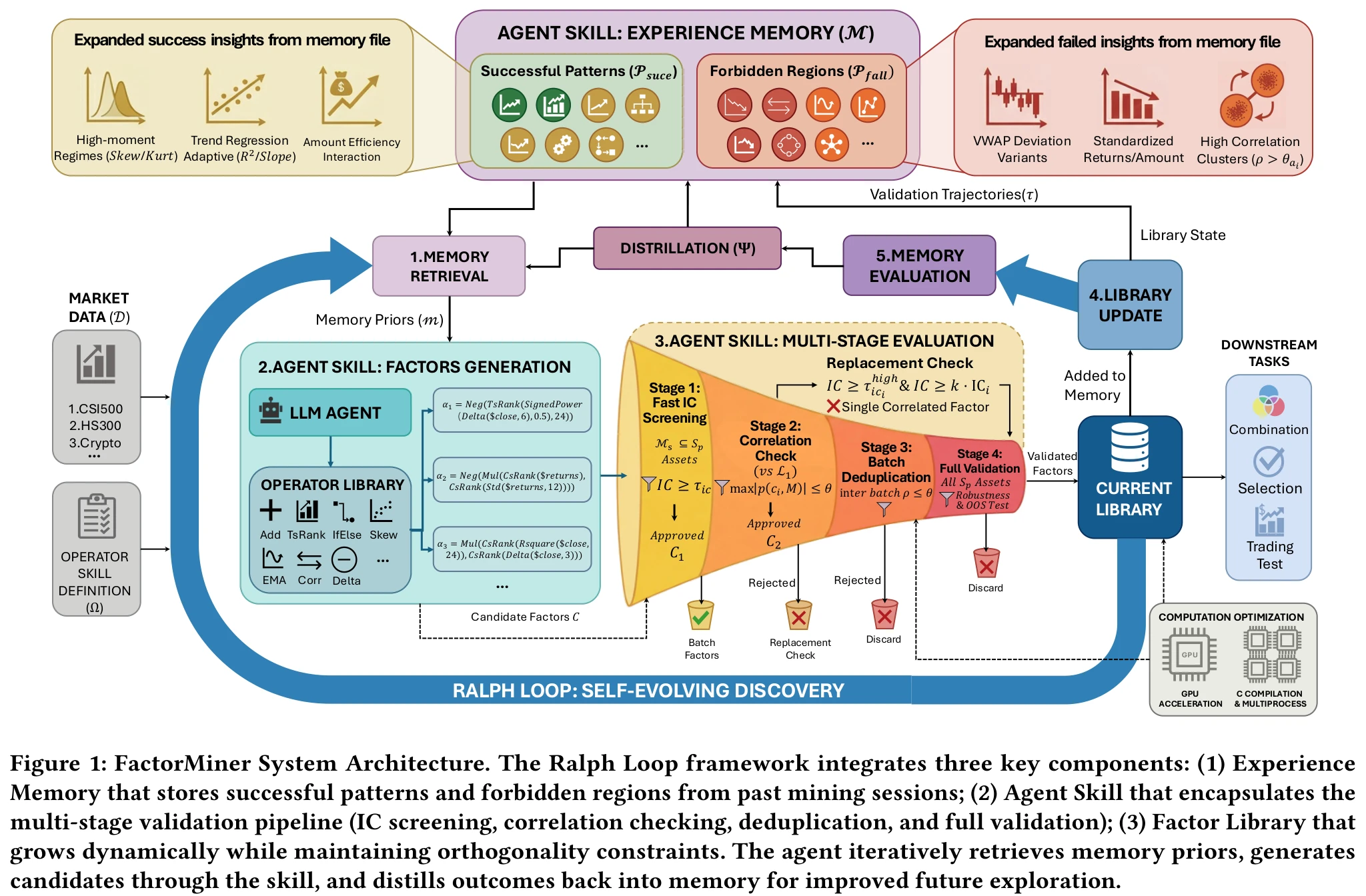
Skill 架构
Skill 包含一个 60+ 算子的 operator library(如 TsRank、Rsquare 等),以及一条标准化的多阶段验证流程:
- Stage 1: Fast IC screening,在小资产子集上快筛 \(|IC| \geq \tau\)
- Stage 2: Correlation check,对全库做 \(\max_{\beta \in \mathcal{L}} |\rho(\alpha, \beta)| < \theta\)
- Stage 2.5: Replacement check,候选和现有因子高相关但自身更好时触发替换
- Stage 3: Batch deduplication,本批候选之间也去重
- Stage 4: Full validation,全资产 OOS 测试
Skill 设计把 “agent reasoning” 和 “工具执行” 完全解耦:LLM 只负责提出候选公式,IC 计算、相关性检验、admit 判定全部由确定性 Python 代码完成。论文称之为避免 calculation hallucination:LLM 没机会编造一个不存在的 IC 数字。
Experience Memory
Memory 记录两类内容:
- Successful Patterns \(\mathcal{P}_{\text{succ}}\):反复入库的因子模板,比如"用 Skew/Kurt 做高阶矩 regime"、“用 Rsquare 做趋势回归自适应”
- Forbidden Regions \(\mathcal{P}_{\text{fail}}\):和现有库相关性总是超标的方向,比如简单的 VWAP 偏离变体、标准化收益率
Memory 的更新通过三个抽象算子完成:
$$ \mathcal{M}_{t+1}^{\text{form}} = \Phi(\mathcal{M}_t, \tau_t), \quad \mathcal{M}_{t+1} = \Psi(\mathcal{M}_t, \mathcal{M}_{t+1}^{\text{form}}), \quad \mathfrak{m} = \Xi(\mathcal{M}_t, \mathcal{L}_t) $$其中 \(\tau_t\) 是本轮的挖掘轨迹(每个候选的公式、IC、相关性、是否 admit),\(\Phi\) 把轨迹蒸馏成模板,\(\Psi\) 整合到现有 memory,\(\Xi\) 在生成阶段把 memory 检索成 prompt 中的"推荐方向"和"禁区方向"。
实现上 memory 不是稠密表征也不是 replay buffer,就是若干自然语言模板加 canonical example,配合当前库状态做检索。
Ralph Loop
整个流程论文叫 Ralph Loop:retrieve → generate → evaluate → distill 循环。每轮 agent 先从 memory 取先验,按先验生成一批候选公式,过 multi-stage 流程,把结果(入库的、因相关性被拒的、因 IC 不够被拒的)蒸馏回 memory,再开始下一轮。
LLM backbone 是 Gemini 3.0 Flash。整套循环跑在自研的 GPU 加速算子库上。
memory 与 skill 的作用机制
memory 起到的作用是改变 prompt 给 LLM 的采样分布。论文写成:
$$ \pi(\alpha | \mathfrak{m}), \quad \mathfrak{m} = \Xi(\mathcal{M}_t, \mathcal{L}_t) $$\(\mathfrak{m}\) 把检索到的"成功模板"和"禁区"塞进 prompt,让 LLM 生成时偏向 \(\mathcal{P}_{\text{orth}}\) 这块区域。这不是严格的搜索空间裁剪,是采样分布的偏置:没有 memory 时 LLM 也有自己的预训练先验,但缺少对当前库状态的感知,越到后期重复撞 forbidden region 的概率越高。
skill 的解耦设计另外解决了 LLM agent 在数值计算上的不可靠问题。让 LLM 自己算 IC 会出现编造数字的情况;把这些计算外包给 deterministic skill,agent 只在符号层面操作,可靠性才能立住。
实验结果
数据集是 A 股 CSI500、CSI1000、HS300 加 Binance 上 64 个加密资产,全部用 10 分钟 bar,2024 训练,2025 测试,预测目标是下一根 10 分钟的开收价格变化。
Baseline 六个:Random Formula (RF)、Alpha101 Classic、Alpha101 Adapted 高频版、GPLearn、AlphaForge、AlphaAgent。所有方法用同样的 operator library、admission 规则、评估引擎,对比的是搜索算法本身。
Top-40 因子库样本外表现(IC % / ICIR):
| 方法 | CSI500 | CSI1000 | HS300 | Crypto |
|---|---|---|---|---|
| Random Formula | 2.68 / 0.25 | 2.88 / 0.30 | 1.45 / 0.09 | n/a |
| Alpha101 Classic | 4.49 / 0.42 | 4.86 / 0.50 | 2.11 / 0.14 | n/a |
| Alpha101 Adapted | 5.06 / 0.43 | 5.32 / 0.49 | 2.40 / 0.15 | n/a |
| GPLearn | 6.04 / 0.43 | 5.86 / 0.48 | 4.12 / 0.16 | 2.50 / 0.15 |
| AlphaForge | 4.48 / 0.38 | 4.64 / 0.42 | 3.53 / 0.25 | 2.52 / 0.16 |
| AlphaAgent | 5.90 / 0.46 | 6.21 / 0.51 | 4.69 / 0.30 | 2.86 / 0.17 |
| FactorMiner | 8.25 / 0.77 | 7.78 / 0.76 | 7.46 / 0.38 | 3.82 / 0.28 |
四个市场 IC 和 ICIR 都是最优。CSI500 上对最强 baseline AlphaAgent 的相对提升约 40% (IC)、67% (ICIR),HS300 上对 AlphaAgent 提升约 59%(vs 老 Alpha101 Classic 则超过 3 倍)。HS300 整体 IC 水平低于 CSI500,原因是大盘股 microstructure 信号比中小盘更弱。
Crypto 上 FactorMiner 对 AlphaAgent 的提升约 34%,幅度小于 A 股。论文给出的解释是 skill 编码的是跨市场的微观结构通性而不是单市场的特异规则,所以从 A 股训得的配置能直接迁移过去。但 Random Formula 和 Alpha101 在 Crypto 上没跑(论文表里没填),所以"完整 baseline 横扫"只到 LLM 类方法这层。
学习集成与 IC 加权的边际收益
论文还把库丢给 Lasso 和 XGBoost 做选股。多数 baseline 上学习模型比等权和 IC 加权有明显提升;FactorMiner 上的提升非常有限,CSI500 上 EW 和 ICW 的 ICIR 是 1.29/1.31,Lasso 和 XGBoost 是 1.21/1.29,甚至略有下降。原因是 FactorMiner 的库构造时已经做了正交化(Stage 2 + Stage 3),简单等权就吃掉了大部分可利用的预测信号,learned selection 没多少残留空间。
Memory 的消融
论文把 \(\Phi, \Psi, \Xi\) 三个 memory 算子关掉,跑 No Memory 版本对比。
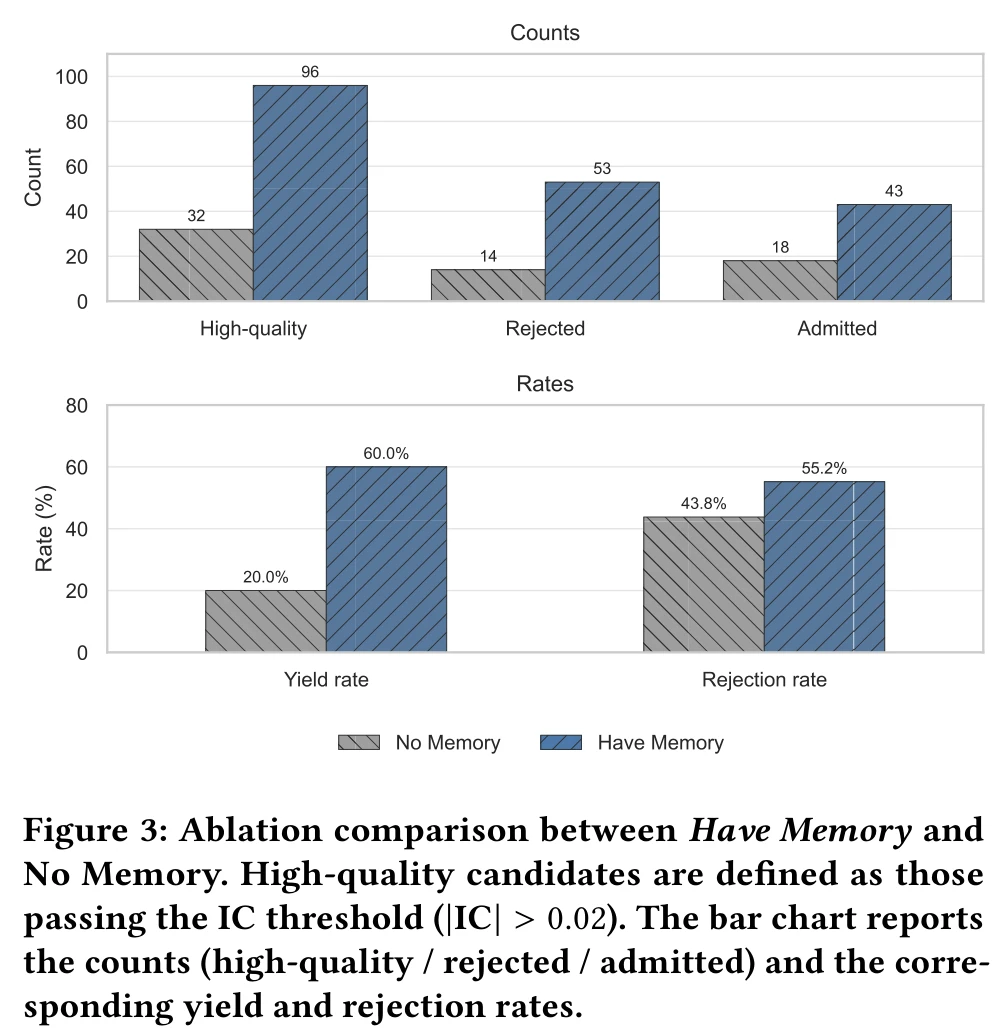
读数:
- High-quality 候选(\(|IC| > 0.02\)):96 vs 32,3.0×
- Admit:43 vs 18,2.4×
- Yield rate(高质量候选占比):60.0% vs 20.0%
- Rejection rate(高质量候选中因冗余被拒的比例):55.2% vs 43.8%
Yield rate 提升说明 memory 把搜索拉到了更可能命中的区域。Rejection rate 反而升高这个点更有意思:memory 引导生成的候选 IC 更高,但更容易和已有库相关,所以需要更激进的去重才能维持正交性。这正是 \(\Psi\) 算子在工作,把单纯追求 IC 的搜索转成 IC 和正交性的联合优化,直接对应 \(\mathcal{P}_{\text{orth}}\) 那条约束。
阈值方面这组消融用了较松的 \(|IC| > 0.02\) 和 \(\theta = 0.85\),论文说是为了保证样本足够做对比,主实验用了更严的阈值。
GPU 算子库与评估开销
论文实现了一套 GPU 加速算子库,对比 Pandas、C 编译版(Bottleneck)、GPU 三个 backend 在 CSI500 (12,610 × 500) 数据上的算子计算时间:
- TsRank:1843ms (Pandas) → 393ms (C) → 31ms (GPU),GPU 加速 59×
- TsCorr / TsStd 等:8–59× 加速区间
- C 版平均也比 GPU 慢 5.4× (1092ms vs 202ms)
整体效果是评估 1000 个候选因子从 70 分钟(Pandas)压到 6 分钟。论文称之为 “qualitative enabler”:没有这套加速,整个 retrieve-generate-evaluate-distill 循环根本不可能在合理时间内迭代。很多 LLM agent 论文跳过底层计算效率,但因子挖掘是 evaluation-bound 任务,eval 太慢循环就转不起来。
LLM 一律用 Gemini 3.0 Flash,没有针对挖因子做 fine-tuning。论文未报告调用次数和 token 成本。
局限
论文最后两节列了几条 limitation:
- 没有和端到端的神经预测模型做直接对比,比如把 110 个因子作为特征丢进 LightGBM,对比直接用 raw OHLCV 训神经网络
- 没有 transaction cost-aware 的回测,只评估 IC/ICIR 这类信号质量指标
- Memory 更新是 offline 的,展望是做 online memory updates 以适应非平稳市场
- A 股训练得到的 memory 直接迁移到 Crypto,但有效性是经验性的,没给理论保证
实际更关心的两个问题论文没回答:一是 LLM 提示词的工程量有多大、对结果的鲁棒性如何;二是 110 个因子在 2025 年继续推到 2026 年还能保持多少 IC。第一点是工程复现门槛,第二点是因子衰减问题。
小结
FactorMiner 解决的问题是"因子库越大越难加新因子",路径是把搜索过程从无记忆的随机/进化采样改成有 memory 引导的 agent 循环。两个核心组件 skill 和 memory 各司其职:skill 保证数值计算可靠,memory 把过去的探索经验沉淀成下一轮的先验。
实验上对比 GPLearn、AlphaForge、AlphaAgent 等近期工作,四个市场 IC 和 ICIR 都最优,A 股训得的 memory 还能零样本迁移到加密市场。消融实验直接证明了 memory 的作用:yield rate 从 20% 提到 60%,admit 数从 18 涨到 43。论文一并放出了 110 个 A 股高频因子库,对想做后续研究的人是一个直接可用的工件。
延伸阅读:
- AlphaGPT 论文简读:LLM 参与因子挖掘的早期工作
- AlphaAgent 论文简读:多 agent 框架与抗衰减
- QuantaAlpha 论文简读:trajectory 视角下的自进化挖掘