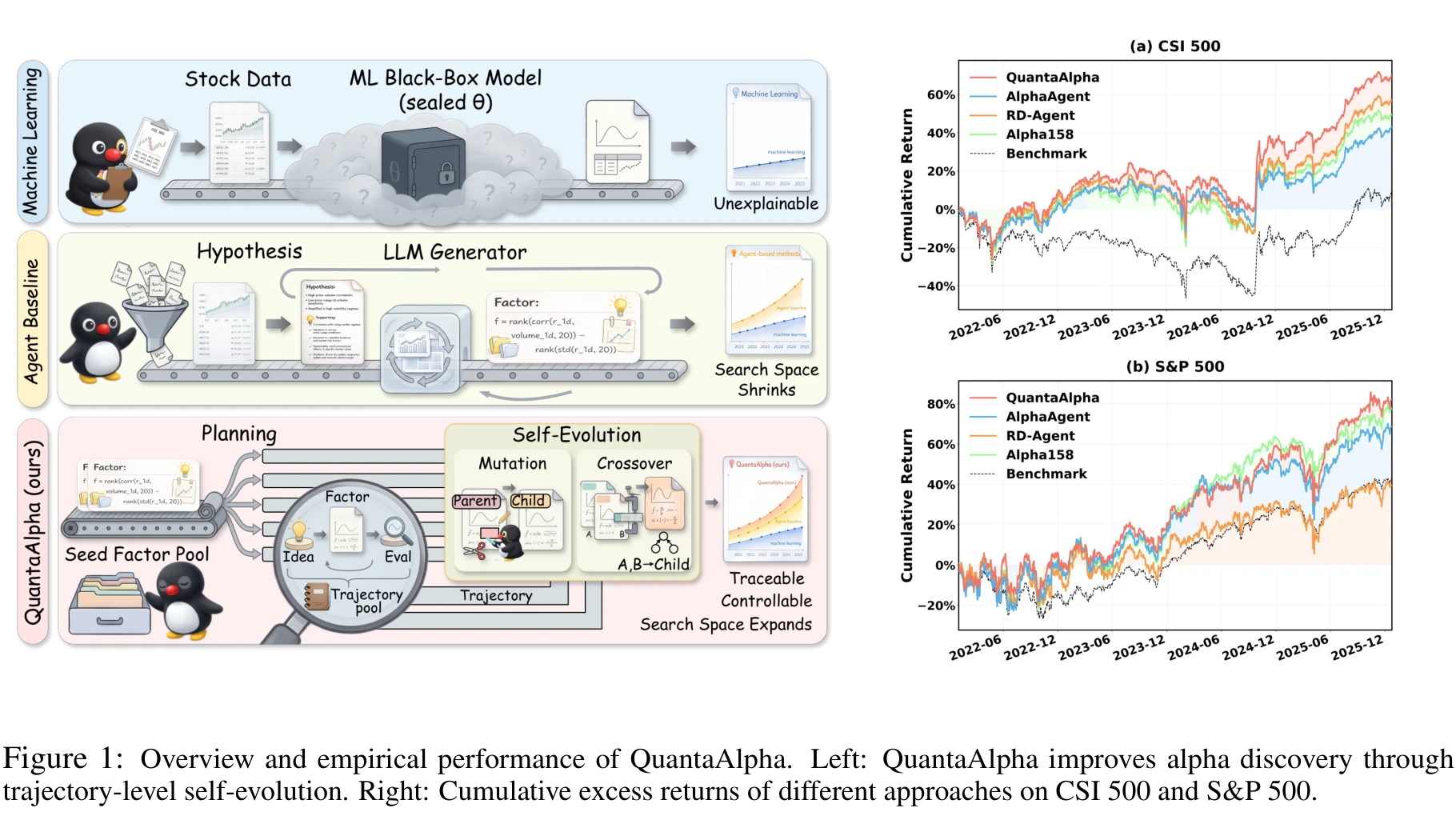
AlphaAgent tackled “LLM-generated factors look too similar, accelerating alpha decay” with factor-level regularization. QuantaAlpha (arXiv 2602.07085) operates one level up: instead of constraining a single generation, treat the full “hypothesis → factor → backtest” pipeline as a trajectory, and apply mutation and crossover between trajectories. On CSI 300 with GPT-5.2 it lands IC 0.0472, ARR 4.68%, MDD 11.8%. Zero-shot transfer to CSI 500 and S&P 500 keeps 40.28% and 19.1% cumulative excess return respectively.
Three persistent issues in LLM-driven alpha mining
The standard recipe used by recent agentic systems looks like: generate a market hypothesis, translate it into a factor expression, backtest, and refine. AlphaAgent and RD-Agent both follow this. The paper distills three issues that survive across them all:
Fragile controllability. Refinement is steered entirely by backtest scores, which are themselves noisy. Models drift along the noise and end up with factors that no longer reflect the original economic mechanism, just an artifact of overfitting the backtest.
Limited trustworthiness. Most methods re-sample from the current context every round without explicitly inheriting validated rationales from earlier rounds. There is no traceable lineage, so it is hard to explain why a particular factor came from a particular line of reasoning. Audit and reuse both suffer.
Constrained exploration. Search keeps circling the neighborhood of seed factors, producing structurally similar candidates and worsening crowding. The hypothesis space is large in theory; in practice only a small region is covered.
QuantaAlpha’s response: shift the unit from “individual factor” to “complete mining trajectory”, and borrow mutation and crossover from genetic algorithms to drive evolution.
The QuantaAlpha framework: four parts, one trajectory
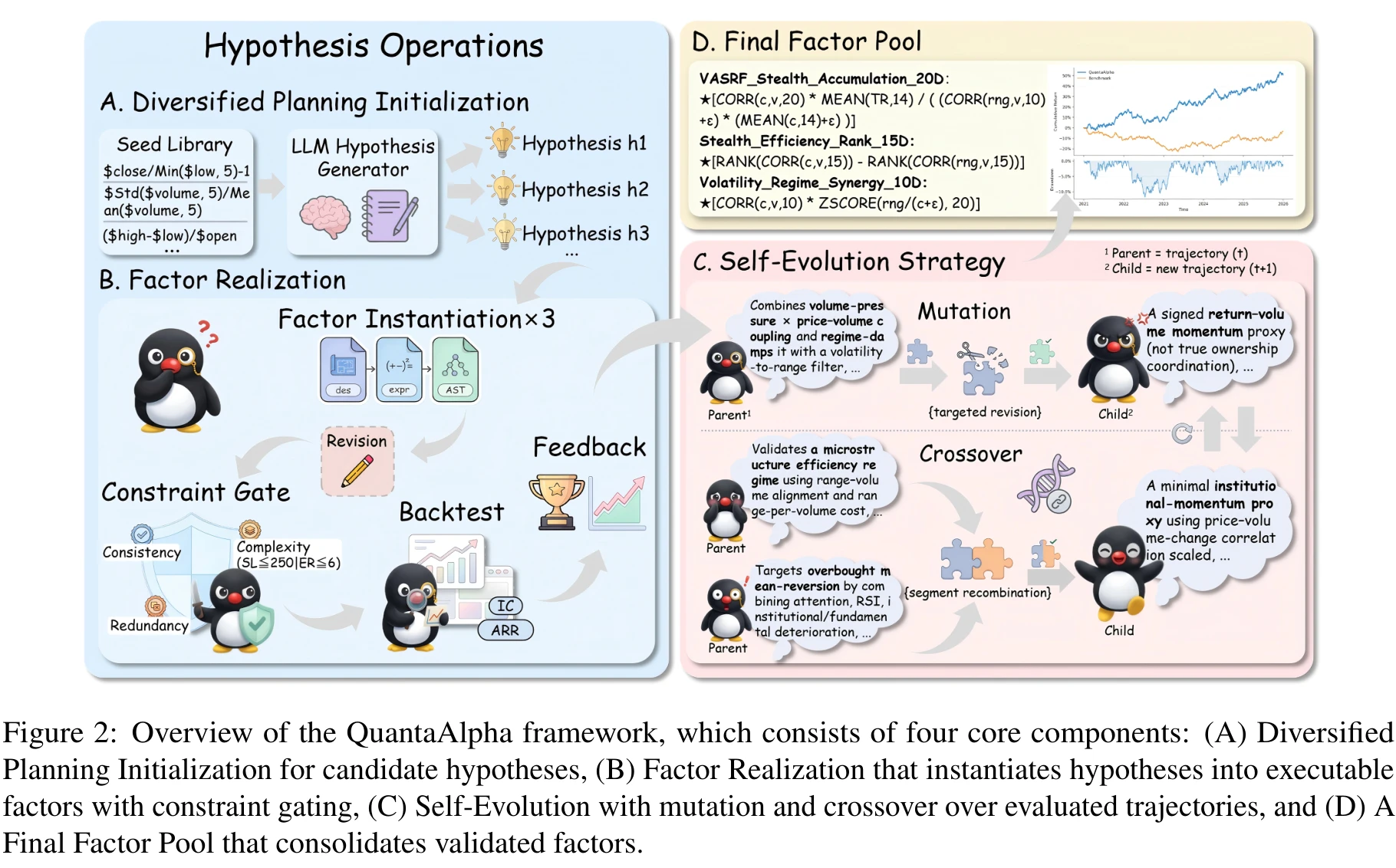
The system splits into four components:
- A. Diversified Planning Initialization. An initialization agent starts from a seed pool (an Alpha158(20) subset grouped by low correlation) and proposes a set of complementary initial hypotheses. The agent is asked to vary signal sources (price vs. volume), time scales (short vs. long), and mechanism types (momentum vs. reversion vs. regime-conditioned) to spread the search frontier.
- B. Factor Realization. The hypothesis-to-expression-to-code pipeline, gated by consistency, complexity, and redundancy checks.
- C. Self-Evolution. On top of existing trajectories, select parents by reward, locally rewrite via mutation, recombine high-reward segments via crossover, and iterate.
- D. Final Factor Pool. Validated factors accumulated across evolution are consolidated and handed to a downstream LightGBM for combination.
The next three sections unpack the trajectory formulation, controllable factor construction, and the self-evolution operators.
Formalizing alpha mining as trajectories
The traditional formulation writes alpha mining as:
$$ f^* = \arg\max_{f \in \mathcal{F}} \mathcal{L}\big(f(X), y\big) - \lambda R(f) $$QuantaAlpha does not optimize at the factor level. It defines a mining trajectory:
$$ \tau = (s_0, a_0, s_1, a_1, \ldots, s_n) $$\(s_0\) is the initial context (market data, user seeds), \(a_i\) is the action taken by the multi-agent system at step \(i\) (generate hypothesis, build factor, repair code, backtest), and \(s_n\) is the terminal state containing this run’s evaluated result. The trajectory reward sits on the terminal:
$$ R(\tau) = \mathcal{L}\big(f_\tau(X), y\big) - \lambda R(f_\tau) $$The learning objective becomes finding a trajectory generation policy \(\pi\) that maximizes expected reward:
$$ \pi^* = \arg\max_\pi \mathbb{E}_{\tau \sim \pi}\big[R(\tau)\big] $$This abstraction is not just packaging. Once each complete run is a manipulable object, “which step went wrong” and “which segments compose well together” become things you can intervene on locally. The paper’s critique of AlphaAgent and RD-Agent centers on “lack of traceable lineage”, which essentially means the intermediate decision chain is not preserved for reuse in the next round.
Controllable factor construction: symbolic expressions, AST, three gates
Asking an LLM to write factor code directly is brittle: syntax errors, dependency mismatches, semantic drift from the hypothesis. QuantaAlpha takes a more compiler-style path.
Symbolic expression plus AST. The factor agent first maps hypothesis \(h\) to a structured semantic description \(d\), composes a symbolic expression \(f\) over the operator library \(\mathcal{O}\), and parses it into an AST \(T(f)\). Leaves bind to raw fields ($high, $volume), internal nodes are operator instances (TS_MIN, SMA, RANK), and the final step compiles to executable code \(c\). A compilation failure triggers LLM-based repair, but the semantics of \(f\) must be preserved.
Consistency verification. A verifier checks two things: alignment among hypothesis \(h\), semantic description \(d\), and symbolic form \(f\); fidelity between \(f\) and code \(c\). Any mismatch sends the offending component back for rewrite, up to a retry budget. This gate primarily blocks the silent drift of “hypothesis claims to capture liquidity but the code never touches volume”.
Complexity control. An explicit complexity score:
$$ C(f) = \alpha_1 \cdot SL(f) + \alpha_2 \cdot PC(f) + \alpha_3 \cdot \log\big(1 + |\mathcal{F}_f|\big) $$\(SL\) is symbolic length, \(PC\) counts free parameters (windows, thresholds), \(\mathcal{F}_f\) is the feature set used by \(f\). The point is to constrain expressions that look impressive but are actually overfitting.
Redundancy control. Structural similarity between two factors is measured by maximum common subtree size on their ASTs:
$$ s(f_i, f_j) = \max_{S_i \subseteq T(f_i),\, S_j \subseteq T(f_j),\, S_i \cong S_j} |V(S_i)| $$For a candidate \(f\) the maximum similarity against an existing alpha zoo \(\mathcal{Z}\) is \(S(f) = \max_{\zeta \in \mathcal{Z}} s(f, \zeta)\); above threshold it is rejected. After structural deduplication, a second pass runs output correlation filtering on the 2021 validation panel: any pair above an absolute correlation threshold keeps only the higher-RankIC factor.
This two-stage “structural plus functional” deduplication is more robust than either alone. Pure structural matching can miss two ASTs that look different but behave almost identically (equivalent rewrites); pure output matching deletes factors that look alike but capture different mechanisms. Stacking both checks lands closer to what “non-redundant” actually means in production.
Self-evolution: how Mutation and Crossover work
Initialization produces a trajectory pool \(\mathcal{T}_0 = \{\tau_j^0\}_{j=1}^{N_{init}}\). Every subsequent round applies two primitives.
Mutation: targeted repair. Given a trajectory \(\tau\), the agent performs self-reflection to localize the step \(k\) most responsible for the low terminal reward, then rewrites only \(a_k\) (or a short local segment), freezing the prefix and regenerating the suffix conditioned on the new prefix:
$$ \tau_{child} = \big(s_0, a_0, \ldots, s_k, \text{Refine}(a_k), s_{k+1}, a_{k+1}, \ldots, s_n\big) $$The rewrite may touch the hypothesis itself, the symbolic expression, or the compiled code. Even imperfect localization gives a directional search signal that is more likely to jump to a different region of factor space than blind re-generation. This is the inductive bias that actually does the work in QuantaAlpha: treat the specific failed step as signal, not as noise to be discarded wholesale.
Crossover: stitching high-reward segments. Select a parent subset \(\mathcal{P}_{i-1} \subseteq \mathcal{T}_{i-1}\) by trajectory reward, then synthesize a child trajectory by composing segments that consistently contribute to high cumulative reward from \(k\) parents:
$$ \tau_{child} = \text{Crossover}\big(\tau^{(1)}, \ldots, \tau^{(k)}\big) $$The segments can be hypothesis templates, construction patterns, or repair actions. The point is to explicitly inherit validated decisions, which directly addresses the “limited trustworthiness” critique: crossover children come with a lineage, you can name which parents contributed which segments.
In the ablations, mutation dominates (removing it drops IC by 0.0079 and ARR by 1.26%); crossover contributes less but consistently. The paper attributes this to the five-iteration budget; the recombination payoff from crossover needs a longer evolutionary horizon to fully show up.
CSI 300 main results: the real gap vs. RD-Agent and AlphaAgent
Setup: CSI 300, 2016-01 to 2020-12 training, 2021 validation, 2022-01 to 2025-12-26 testing (the paper’s test window literally ends last December). All LLM-based methods feed roughly 150 validated factors into the same downstream LightGBM, so the comparison is at the factor-pool level rather than “who picked best”. On GPT-5.2:
| Method | IC | Rank IC | ARR (%) | MDD (%) |
|---|---|---|---|---|
| RD-Agent | 0.0286 | 0.0250 | 3.58 | 16.76 |
| AlphaAgent | 0.0347 | 0.0334 | 1.11 | 13.89 |
| QuantaAlpha | 0.0472 | 0.0459 | 4.68 | 11.80 |
Versus RD-Agent, IC improves by 0.0186, ARR by 1.10%, MDD drops by 4.96%. The paper attributes this to RD-Agent having no generation-stage regularization at all, while both QuantaAlpha and AlphaAgent do (though the specific constraints differ), leaving RD-Agent worse on both semantic drift and implementation reliability.
Versus AlphaAgent (which also has generation-stage regularization, mainly AST dedup, hypothesis alignment, and complexity control), IC further improves by 0.0125, ARR by 3.57%, MDD drops by 2.09%. This delta is attributed to trajectory-level self-evolution: mutation expands mechanism-level exploration, crossover reuses validated construction patterns, lifting both the yield of high-quality factors and the stability of the evolution process.
One detail worth flagging: with Claude-4.5-Sonnet, QuantaAlpha’s IC is 0.0445, slightly below DeepSeek-V3.2’s 0.0461. The paper’s explanation is backbone-specific: Claude produces longer feedback outputs, which leaves fewer prior trajectories fitting within a fixed context budget, and its mutations tend to be more local; DeepSeek is more willing to propose larger exploratory jumps. The fact that model personality measurably shapes agent behavior is something LLM agent papers rarely admit out loud.
Cross-market transfer and alpha decay
![]()
Factors mined on CSI 300 are deployed unchanged on CSI 500 and S&P 500: cumulative excess return reaches 40.28% on CSI 500 and 19.1% on S&P 500. The paper attributes transferability to two design choices: the factors use standard OHLCV-based operators with no dependence on market-specific micro-structure fields; daily cross-sectional normalization absorbs scale differences across markets.
The alpha decay comparison is the more interesting result. 2023 was a sharp regime shift in A-shares: prior years were driven by institutional “core assets” where conventional momentum and reversion worked; in 2023 the market rotated to small-caps and themes, with louder intraday noise, more frequent overnight gaps, and weaker trend persistence. Every baseline collapses that year; Alpha158’s IC drops to near zero. QuantaAlpha stays above 0.045 through the shift (reading off Figure 4), with almost no drop. The paper’s explanation is that the discovered factors (for example, Mean-Reverting Range Deviation, using recent high-low range deviation as a reversion signal, and Overnight Gap Structure, treating overnight jumps as a separate information-absorption window) reflect deeper microstructure properties such as volatility clustering and overnight information incorporation that hold across capitalization styles.
This is the most underrated result in the paper: cross-market transfer is eye-catching, but cross-regime stability is harder. The former only requires factors to be “general enough statistical features”; the latter demands they capture micro behaviors that hold across regimes.
Iterative efficiency
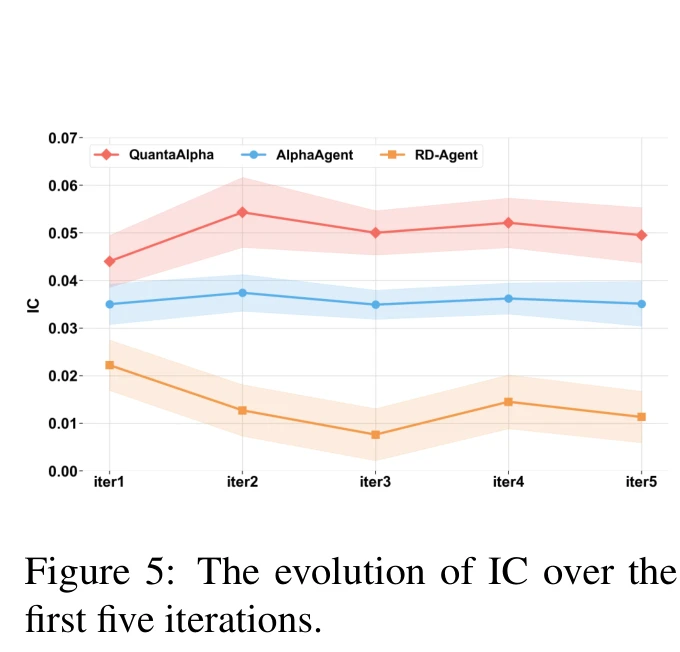
Tracking IC distribution across five iterations: QuantaAlpha pushes IC to around 0.054 by iter 2 and stays near 0.05; AlphaAgent flatlines around 0.035; RD-Agent actually declines, hitting roughly 0.008 by iter 3 (reading off the chart). The figure directly contradicts the casual assumption that “more LLM agent iterations is always better”. Iteration only pays off when there is a structured mechanism for reuse; without it, you mostly amplify noise.
The paper also reports a longer-horizon result: predictive performance does not begin to decay until roughly iteration 15. Five iterations is nowhere near the ceiling; trajectory-level evolution keeps surfacing new effective patterns.
A few takeaways worth keeping
First, the ceiling on alpha mining is not single-generation quality, it is “how do you reuse validated decisions from previous runs”. AlphaAgent and RD-Agent hit a plateau quickly because every round restarts from near zero. QuantaAlpha makes the trajectory a first-class object and applies mutation and crossover to it, closing the implicit feedback channel.
Second, AST subtree matching plus output correlation filtering is much more useful than either alone. Structural dedup blocks “the same factor with new packaging”; output dedup merges “behaves identically despite looking different”. You need both to get close to what dedup should mean in practice.
Third, cross-market transfer and cross-regime stability are different problems, and the second one is harder and more valuable. Zero-shot transfer to S&P 500 is common in LLM alpha mining papers. Holding IC stable through the A-share 2023 style rotation is rare, and it hints the discovered factors touch deeper microstructure rather than statistical arbitrage.
Fourth, model choice noticeably changes what the agent does. Same framework, Claude does small local mutations, DeepSeek does big jumps, and IC differs by 0.0016. When designing this kind of agentic pipeline, “which base model” deserves the same priority as “which hyperparameter”.
Engineering takeaways from QuantaAlpha
For LLM-driven alpha mining, QuantaAlpha offers a relatively clean paradigm: model alpha mining as trajectories rather than factors, evolve them with mutation and crossover in trajectory space, and use consistency, complexity, and redundancy gates to guard generation quality. IC 0.0472 on CSI 300 is among the strongest results currently available, and the cross-regime stability is unusually solid.
If you only transplant one thing into your own agent system, start with mutation’s failure localization: have the agent explicitly name which step in the previous trajectory dragged the whole run down, then rewrite only that step. This is a prompt-level change that does not depend on a particular LLM. Crossover’s payoff needs a longer evolution window; pick it up after mutation is in place.
Related reading: AlphaAgent: Regularized Exploration Against Alpha Decay, AlphaGPT paper review, Alpha101 factor library overview.