Formulaic alpha factor mining hits a wall once the library grows past a few dozen factors: new candidates have decent IC, but correlation against the existing library always exceeds the threshold, so nothing gets admitted. AlphaGPT, AlphaForge, AlphaAgent, and QuantFactor REINFORCE all attack the “generate more candidates” side, while the “the bigger the library, the harder to add new stock” problem still gets little treatment.
FactorMiner (A Self-Evolving Agent with Skills and Experience Memory for Financial Alpha Discovery, 2026/02, arXiv 2602.14670) wraps the mining loop into an agent skill and maintains an experience memory that records “which directions kept hitting walls, which templates keep paying off,” so every round the agent samples with a prior built from past wins and losses. On CSI500, the top-40 library reaches IC 8.25% and ICIR 0.77, about 40% relative to AlphaAgent’s 5.90%/0.46.
Problem setup
The paper names the bottleneck “Correlation Red Sea.” Formally: every new factor \(\alpha\) must satisfy
$$ \mathcal{P}_{\text{orth}} = \\{ \alpha \in \mathcal{P} : \max_{\beta \in \mathcal{L}} |\rho(\alpha, \beta)| < \theta \\} $$As \(\mathcal{L}\) grows, the feasible region \(\mathcal{P}_{\text{orth}}\) shrinks fast. Standard search methods (GP, RL) have no mechanism for this: they don’t remember which regions were already explored or which directions keep getting rejected, so they keep walking the same loops.
Worse, these methods treat each factor as an independent optimization, measured only by individual IC/ICIR, without regard for how a new factor interacts with the existing library. Even high-quality individual factors end up redundant once admitted.
Method
FactorMiner has two layers: domain knowledge encapsulated as an agent-reusable skill, and past exploration distilled into a memory; a retrieve/generate/evaluate/distill loop ties the two together.
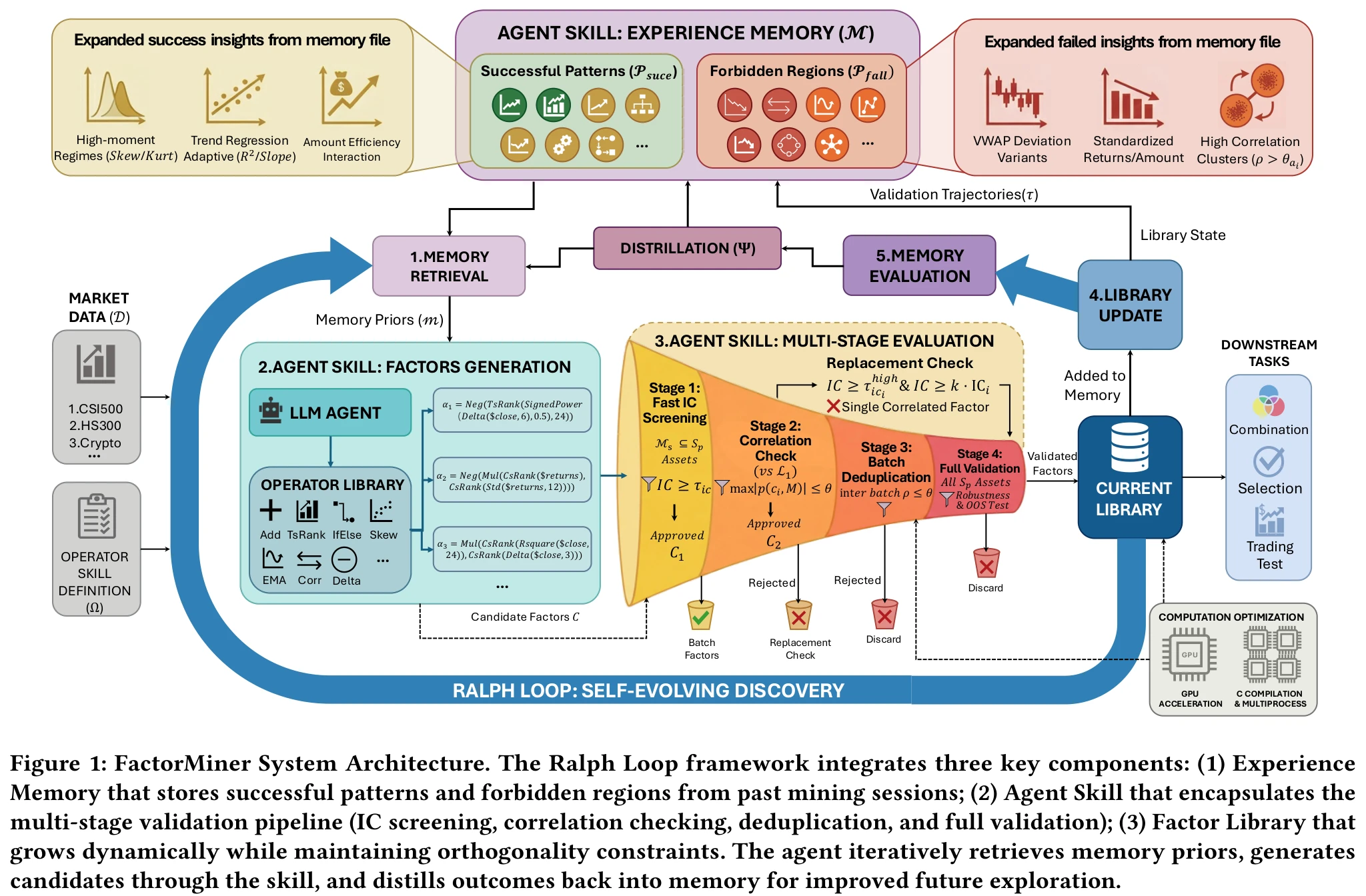
Skill architecture
The skill includes an operator library of 60+ financial operators (TsRank, Rsquare, etc.) plus a standardized multi-stage validation pipeline:
- Stage 1: Fast IC screening on a small asset subset, \(|IC| \geq \tau\)
- Stage 2: Correlation check against the full library, \(\max_{\beta \in \mathcal{L}} |\rho(\alpha, \beta)| < \theta\)
- Stage 2.5: Replacement check, triggered when the candidate is highly correlated with an existing factor but strictly better
- Stage 3: Batch deduplication across the current candidate batch
- Stage 4: Full validation, OOS on all assets
The skill decouples “agent reasoning” from “tool execution” completely: the LLM only proposes candidate formulas; IC computation, correlation tests, and admission decisions all run in deterministic Python. The paper calls this avoiding calculation hallucination, since the LLM has no opportunity to fabricate an IC number.
Experience memory
Memory stores two kinds of content:
- Successful Patterns \(\mathcal{P}_{\text{succ}}\): factor templates that get admitted repeatedly, e.g. “use Skew/Kurt for higher-moment regime detection,” “use Rsquare for trend-regression adaptivity”
- Forbidden Regions \(\mathcal{P}_{\text{fail}}\): directions whose correlation against the existing library stays above threshold, e.g. simple VWAP deviations, standardized returns
Memory updates use three abstract operators:
$$ \mathcal{M}_{t+1}^{\text{form}} = \Phi(\mathcal{M}_t, \tau_t), \quad \mathcal{M}_{t+1} = \Psi(\mathcal{M}_t, \mathcal{M}_{t+1}^{\text{form}}), \quad \mathfrak{m} = \Xi(\mathcal{M}_t, \mathcal{L}_t) $$where \(\tau_t\) is the current mining trajectory (formula, IC, correlation, admit decision for each candidate), \(\Phi\) distills the trajectory into templates, \(\Psi\) integrates them into existing memory, and \(\Xi\) retrieves memory into the prompt as “recommended directions” and “forbidden directions” during generation.
Memory implementation is neither dense embeddings nor a replay buffer; just natural-language templates with canonical examples, retrieved against the current library state.
Ralph Loop
The paper calls the full cycle a Ralph Loop: retrieve → generate → evaluate → distill. Each round, the agent retrieves priors from memory, generates a batch of candidates conditioned on those priors, runs them through the multi-stage pipeline, then distills the outcomes (admitted, rejected on correlation, rejected on IC) back into memory before the next round.
The LLM backbone is Gemini 3.0 Flash. The full loop runs on the team’s in-house GPU-accelerated operator library.
How memory and skill earn their keep
Memory’s job is to reshape the sampling distribution the LLM works from. The paper writes it as:
$$ \pi(\alpha | \mathfrak{m}), \quad \mathfrak{m} = \Xi(\mathcal{M}_t, \mathcal{L}_t) $$\(\mathfrak{m}\) feeds the retrieved success templates and forbidden regions into the prompt, biasing the LLM toward generating in \(\mathcal{P}_{\text{orth}}\). This is not a strict pruning of the search space, just a re-weighting of the sampling distribution: even without memory the LLM has its own pretraining prior, but it has no awareness of the current library state, so it keeps hitting forbidden regions as the library grows.
The skill decoupling separately fixes LLM agents’ reliability problem on numeric computation. Letting the LLM compute its own IC invites fabricated numbers; outsourcing those to a deterministic skill leaves the agent operating only on the symbolic level, which is where reliability holds up.
Experimental results
Datasets cover three A-share universes (CSI500, CSI1000, HS300) plus 64 major Binance crypto assets, all on 10-minute bars. Training is 2024-Q1 through 2024-Q4, test period is held out in 2025; the prediction target is the next 10-minute open-to-close return.
Six baselines: Random Formula (RF), Alpha101 Classic, Alpha101 Adapted for high-frequency, GPLearn, AlphaForge, AlphaAgent. Every method shares the same operator library, admission rules, and evaluation engine; the comparison isolates the search algorithm itself.
Top-40 library out-of-sample performance (IC % / ICIR):
| Method | CSI500 | CSI1000 | HS300 | Crypto |
|---|---|---|---|---|
| Random Formula | 2.68 / 0.25 | 2.88 / 0.30 | 1.45 / 0.09 | n/a |
| Alpha101 Classic | 4.49 / 0.42 | 4.86 / 0.50 | 2.11 / 0.14 | n/a |
| Alpha101 Adapted | 5.06 / 0.43 | 5.32 / 0.49 | 2.40 / 0.15 | n/a |
| GPLearn | 6.04 / 0.43 | 5.86 / 0.48 | 4.12 / 0.16 | 2.50 / 0.15 |
| AlphaForge | 4.48 / 0.38 | 4.64 / 0.42 | 3.53 / 0.25 | 2.52 / 0.16 |
| AlphaAgent | 5.90 / 0.46 | 6.21 / 0.51 | 4.69 / 0.30 | 2.86 / 0.17 |
| FactorMiner | 8.25 / 0.77 | 7.78 / 0.76 | 7.46 / 0.38 | 3.82 / 0.28 |
FactorMiner leads on IC and ICIR across all four markets. On CSI500, the relative improvement over the strongest baseline AlphaAgent is about 40% on IC and 67% on ICIR; on HS300 it is about 59% over AlphaAgent (and more than 3x over Alpha101 Classic). HS300 IC levels sit lower than CSI500 across the board, because large-cap microstructure signals are weaker than mid- and small-cap.
On Crypto, FactorMiner improves over AlphaAgent by about 34%, smaller than on A-shares. The paper attributes this to skill encoding cross-market microstructure regularities rather than market-specific rules, which is why an A-share-trained setup transfers directly. Note that Random Formula and the two Alpha101 variants were not run on Crypto (the table leaves those cells blank), so the “full baseline sweep” on Crypto only goes as far as the LLM-driven methods.
Diminishing returns from learned selection
The paper also evaluates feeding the libraries into Lasso and XGBoost for stock selection. On most baselines, learned models give a clear lift over equal-weight and IC-weighted ensembles. On FactorMiner, the lift is essentially gone: CSI500 EW and ICW give ICIR 1.29/1.31, while Lasso and XGBoost give 1.21/1.29, slightly worse. The reason is FactorMiner’s library is already orthogonalized at construction time (Stage 2 plus Stage 3), so simple equal-weighting already extracts most of the exploitable predictive signal, leaving learned selection with little residual to work with.
Memory ablation
The paper disables the three memory operators \(\Phi, \Psi, \Xi\) and compares against a No Memory variant.
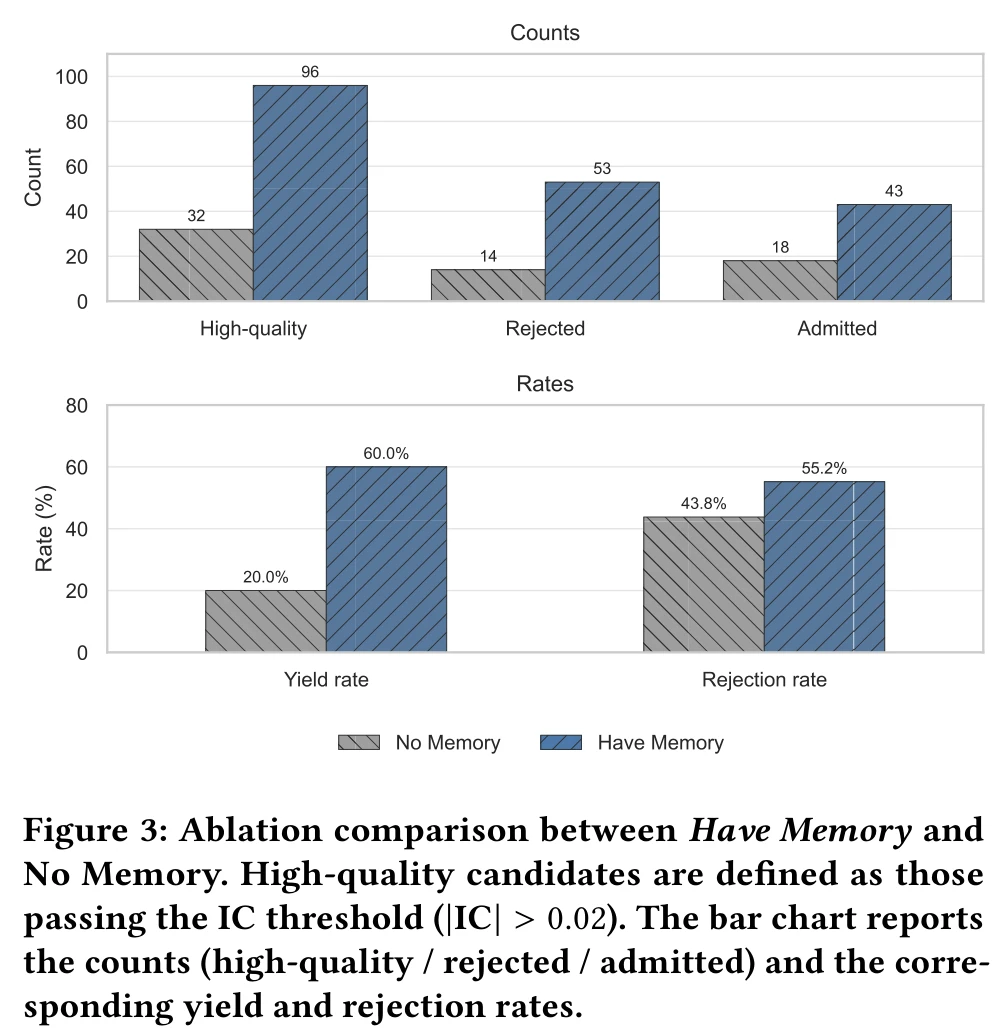
The numbers:
- High-quality candidates (\(|IC| > 0.02\)): 96 vs 32, a 3.0x gap
- Admitted: 43 vs 18, 2.4x
- Yield rate (fraction of high-quality candidates): 60.0% vs 20.0%
- Rejection rate (fraction of high-quality candidates rejected for redundancy): 55.2% vs 43.8%
The yield-rate jump shows memory steers search toward more productive regions. The rejection rate rising is the more interesting point: memory-guided candidates have higher IC but also correlate more easily with the existing library, so deduplication has to work harder to preserve orthogonality. This is exactly what the \(\Psi\) operator is for, converting a single-objective IC search into a joint IC-plus-orthogonality optimization, which corresponds directly to the \(\mathcal{P}_{\text{orth}}\) constraint defined earlier.
On thresholds, this ablation uses the looser \(|IC| > 0.02\) and \(\theta = 0.85\) to keep sample sizes comparable; the main experiments use stricter values.
GPU operator library and evaluation throughput
The paper implements a GPU-accelerated operator library and benchmarks it against Pandas and a C-compiled (Bottleneck) backend on CSI500 (12,610 × 500) data:
- TsRank: 1843ms (Pandas) → 393ms (C) → 31ms (GPU), 59x speedup over Pandas
- TsCorr / TsStd and similar: 8-59x speedup range
- Even the C backend runs 5.4x slower than GPU on average (1092ms vs 202ms)
End-to-end, evaluating 1000 candidate factors drops from 70 minutes (Pandas) to 6 minutes. The paper calls this a “qualitative enabler”: without this acceleration, the retrieve-generate-evaluate-distill loop simply cannot iterate at a reasonable pace. Plenty of LLM-agent papers skip over low-level compute efficiency, but factor mining is an evaluation-bound task. If eval is slow, the loop doesn’t spin.
The LLM is always Gemini 3.0 Flash, no fine-tuning for factor mining. The paper does not report call counts or token cost.
Limitations
The paper’s own limitations section lists:
- No direct comparison to end-to-end neural predictors, e.g. feeding the 110 factors as features into LightGBM versus training a neural net on raw OHLCV directly
- No transaction-cost-aware backtesting; only signal-quality metrics (IC, ICIR) are reported
- Memory updates are offline; online memory updates for non-stationary markets are listed as future work
- A-share-trained memory transfers to Crypto empirically without theoretical justification
Two practical questions the paper doesn’t address: how much prompt-engineering effort the setup demands and how robust results are to prompt variation; and how well the 110 factors hold up beyond 2025 into 2026 (the factor-decay question). The first sets a reproduction barrier, the second is the question every practitioner asks.
Takeaway
FactorMiner targets the “library-growth saturation” problem and replaces memoryless random or evolutionary sampling with a memory-guided agent loop. The two core components split cleanly: skill keeps numeric computation reliable, memory turns past exploration into next-round priors.
Empirically, FactorMiner tops GPLearn, AlphaForge, AlphaAgent, and earlier work on IC and ICIR across all four markets, and the A-share-trained memory transfers zero-shot to crypto. The ablation directly shows memory’s contribution: yield rate from 20% to 60%, admit count from 18 to 43. The paper also releases the 110 A-share high-frequency factor library, which is a directly usable artifact for downstream research.
Further reading:
- AlphaGPT Paper Review: early work on LLM-driven factor mining
- AlphaAgent Paper Review: multi-agent framework with anti-decay regularization
- QuantaAlpha Paper Review: self-evolving mining viewed as trajectories