The previous AlphaGPT review left an open question: when everyone uses LLMs to mine factors, how long can those factors stay effective? AlphaAgent (paper, KDD 2025) tackles this head-on. Its core observation: LLM-generated factors lean too heavily on existing knowledge, producing homogeneous signals that crowd the same trades and accelerate alpha decay. The fix is three regularization constraints injected into the factor generation process, forcing the model to explore structurally novel, logically coherent, and complexity-controlled factors.
Alpha Decay: The Central Tension in Factor Mining
The lifecycle of an alpha factor is one of the harshest realities in quantitative investing. Once a factor is discovered, capital piles into the same signal, the excess return gets arbitraged away, and the factor’s predictive power (IC) steadily declines until it stops working. That’s alpha decay.
Genetic programming (GP) factors decay fast because GP tends to overfit historical data and produce overly complex expressions. LLM-based methods (AlphaGPT, RD-Agent) were supposed to do better, but the paper identifies an overlooked problem: LLM pretrained knowledge is itself “public knowledge.” Factors generated from that knowledge inherently lack originality. Everyone using the same LLM with the same operator library produces structurally similar factors, fishing in the same pond.
The paper backs this up with data: on CSI 500, Alpha158 (a standard set of baseline factors) saw its IC decline from 0.022-0.036 in 2021 to near zero by 2024. GP and other LLM methods showed similar decay patterns.
Three Regularization Mechanisms
AlphaAgent’s core contribution is a regularization framework that adds three constraint terms to the factor generation objective:
$$ f^* = \arg\max_{f \in \mathcal{F}} \mathcal{L}(f(X), y) - \lambda \cdot R_g(f, h) $$Here \(\mathcal{L}\) measures predictive performance (IC, etc.), and \(R_g\) is the regularization term with three components: symbolic length SL (complexity control), free parameter count PC (overfitting prevention), and expression regularization ER (combining AST deduplication, hypothesis alignment, and feature count penalty).
AST Deduplication: Structural Originality
Each factor expression is parsed into an abstract syntax tree (AST): leaf nodes are raw features ($close, $volume), internal nodes are operators (TS_MIN, SMA), and edges represent data flow.
The similarity between two factors is defined as the node count of their largest isomorphic subtree:
$$ s(f_i, f_j) = \max_{t_i \subseteq T(f_i), t_j \subseteq T(f_j)} \{|t_i| : t_i \cong t_j\} $$New factors are compared against an existing factor library (e.g., Alpha101). If the AST overlap is too high, the factor is rejected. This forces the LLM beyond trivial variations of known factors and into genuinely new structural combinations.
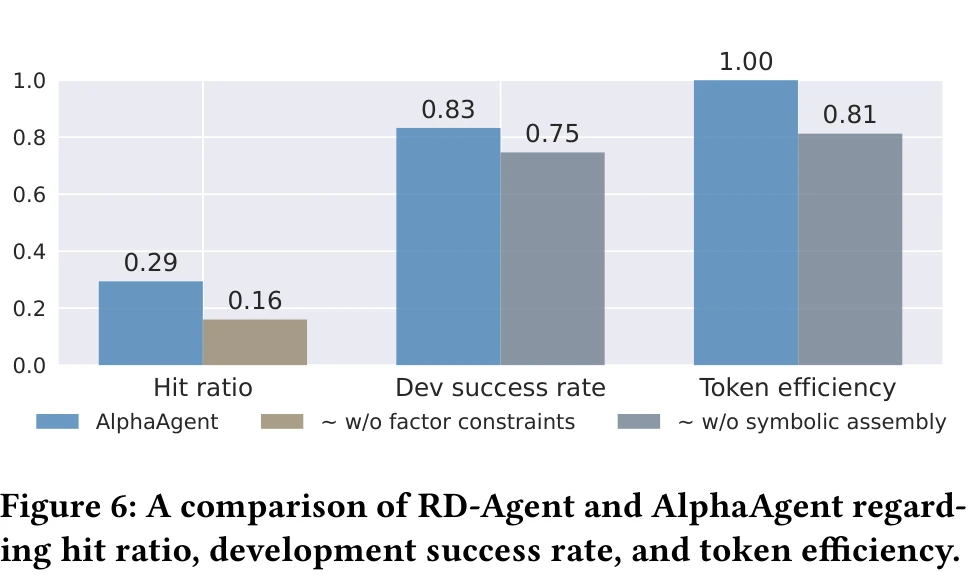
AST deduplication is the most direct contributor to factor originality among the three regularization mechanisms. The paper’s ablation study shows that removing all factor modeling constraints (AST deduplication + hypothesis alignment + complexity control) drops the hit ratio (proportion of generated factors exceeding return thresholds) from 0.29 to 0.16, a 45% decrease.
Hypothesis-Factor Alignment: Semantic Coherence
LLM factor generation is a two-step process: first generate a market hypothesis, then translate it into a factor expression. The problem is that LLMs frequently say one thing and do another. The hypothesis claims to “capture liquidity dynamics,” but the generated factor contains no volume-related operators.
AlphaAgent uses a dual consistency scoring function:
$$ C(h, d, f) = \alpha \cdot c_1(h, d) + (1 - \alpha) \cdot c_2(d, f) $$\(c_1\) checks whether the factor description \(d\) is faithful to the market hypothesis \(h\); \(c_2\) checks whether the factor expression \(f\) is faithful to the description \(d\). Both scores are evaluated by the LLM itself (self-review).
This addresses a practical issue in LLM factor mining: without this alignment layer, LLMs fabricate narratives. The generated factor has no connection to its stated logic. Good backtest results come from overfitting, not from the factor actually capturing the hypothesized market phenomenon.
Complexity Control: Preventing Over-Engineering
The third constraint directly limits factor expression complexity:
- Symbolic length SL(f): penalizes ASTs that are too deep or wide
- Free parameter count PC(f): penalizes factors with too many hyperparameters like rolling windows
The intuition is straightforward: a factor nesting 8 layers of operators with 5 different window parameters is almost certainly overfit, regardless of its backtest IC. Complexity control filters out these over-engineered factors at generation time.
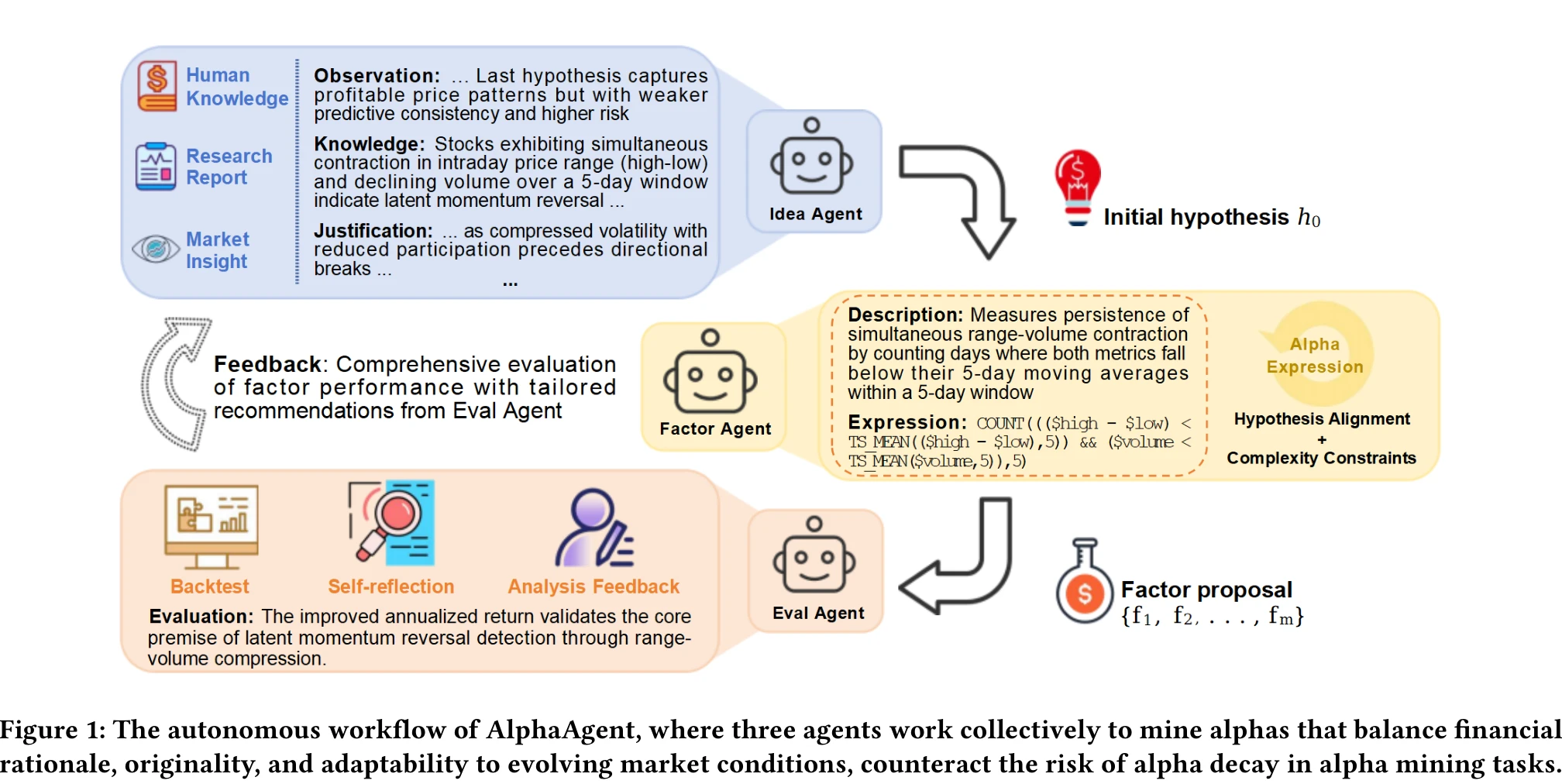
Multi-Agent Architecture
AlphaAgent uses three LLM agents in a closed loop:
Idea Agent generates market hypotheses using chain-of-thought reasoning. Its output has four components: observations (current market state and previous round feedback), knowledge (financial theory: momentum, mean reversion, behavioral finance), justification (connecting observations to knowledge), and specification (concrete parameter suggestions).
Factor Agent translates hypotheses into factor expressions. It maintains an evolving knowledge base recording which factors succeeded, which failed, and why (hypothesis misalignment? structural complexity? too similar to existing factors?). After generating multiple candidates, it filters through the three regularization checks, keeping only those that pass.
Eval Agent backtests factors along three dimensions: predictive power (IC, RankIC), return performance (annualized return, information ratio), and risk control (max drawdown, stability). Results feed back to the Idea Agent as structured feedback, driving the next round of hypothesis refinement.
Each trial runs 5 iteration rounds, and the paper reports results across 20 independent trials.
Experimental Results
The paper tests on CSI 500 (China A-shares) and S&P 500 (U.S. equities). Training period: 2015-2019. Validation: 2020. Test period: 2021 to early 2025. Backtesting uses the Qlib framework with LightGBM as the downstream prediction model. The trading strategy selects the top 50 stocks ranked by predicted returns.
Baselines include LSTM, Transformer, LightGBM, StockMixer, TRA (time-series/tree models), AlphaForge (RL+DL), RD-Agent (LLM, using GPT-4-turbo), plus OpenAI o1 and DeepSeek-R1 (deep reasoning models).
Key results (2021-2024 test period):
| Method | CSI 500 IC | CSI 500 AR | CSI 500 IR | S&P 500 IC | S&P 500 AR | S&P 500 IR |
|---|---|---|---|---|---|---|
| LSTM | 0.0175 | 4.96% | 0.62 | 0.0028 | -1.51% | -0.17 |
| LightGBM | 0.0120 | -1.18% | -0.16 | 0.0011 | -2.64% | -0.42 |
| AlphaForge | 0.0146 | 3.45% | 0.33 | 0.0026 | 2.45% | 0.34 |
| RD-Agent | 0.0113 | 0.78% | 0.07 | 0.0019 | 1.69% | 0.17 |
| DeepSeek-R1 | 0.0132 | 1.58% | 0.21 | 0.0048 | 2.75% | 0.24 |
| OpenAI o1 | 0.0159 | 0.46% | 0.06 | 0.0028 | 2.29% | 0.20 |
| AlphaAgent | 0.0212 | 11.00% | 1.49 | 0.0056 | 8.74% | 1.05 |
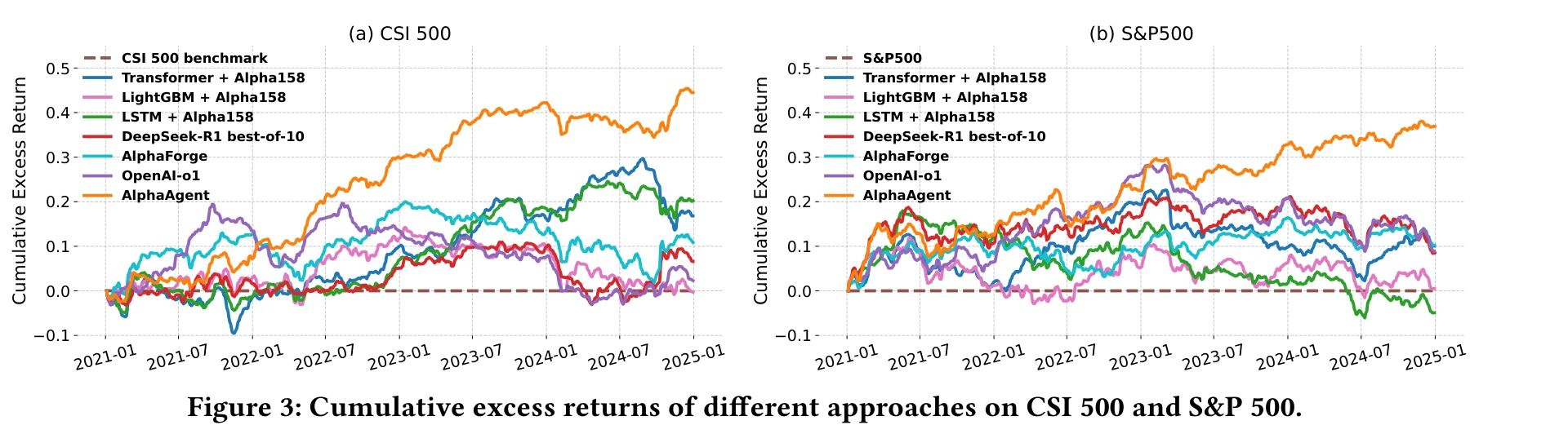
AlphaAgent leads on every metric. CSI 500 cumulative excess return reaches approximately 45%, S&P 500 exceeds 37%. The information ratios of 1.49 and 1.05 far exceed other methods, indicating the returns are not bought with outsized risk.
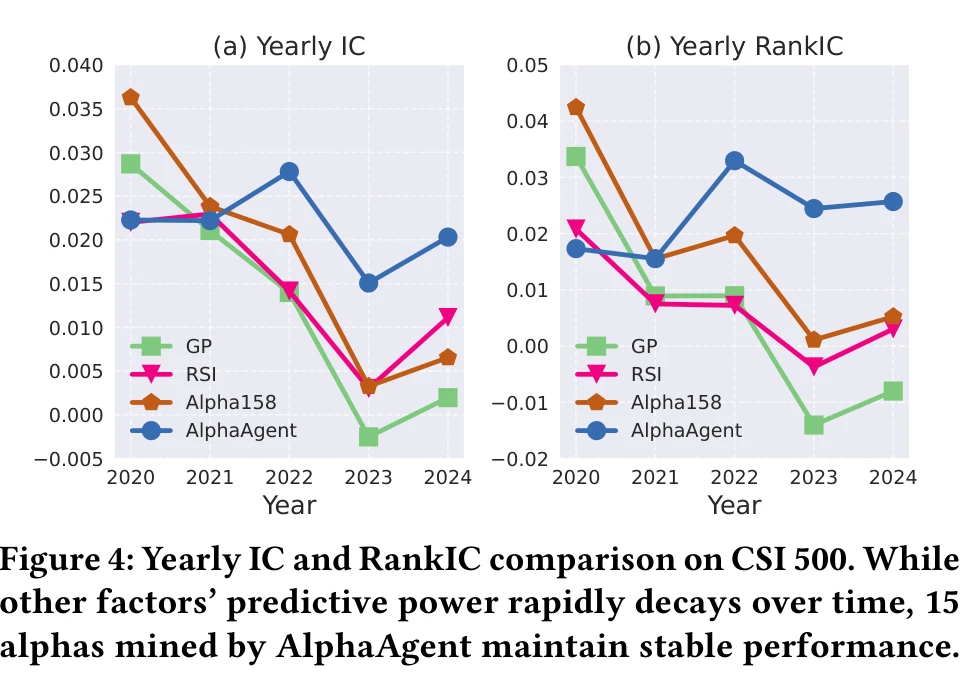
The alpha decay comparison is even more striking. The paper plots yearly IC from 2021-2024: Alpha158’s IC decays to near zero year by year, GP and RD-Agent also decay, but AlphaAgent’s 15 mined factors maintain IC around 0.02 across all four years with no significant decline. This directly validates the three regularization mechanisms against factor decay.
On LLM backbone selection, the paper compares GPT-3.5-turbo (default), Qwen-Plus, and DeepSeek-R1. DeepSeek-R1 performs best as backbone (S&P 500 annualized return 9.19%, max drawdown -6.50%). All backbones show p-values below 0.05 versus RD-Agent, confirming statistically significant improvements.
Limitations and Takeaways
The results are strong, but several points deserve attention.
Backtest is not live trading. The test period is 2021-2025, but these are backtest numbers, not live trades. CSI 500 transaction costs only account for 0.05% (buy) + 0.15% (sell), ignoring market impact and slippage. For a strategy selecting 50 stocks, this assumption is optimistic.
GPT-3.5-turbo as the default backbone. Most experiments use GPT-3.5-turbo, which is no longer the strongest model in 2025. DeepSeek-R1 performs better as backbone, but the paper only runs backbone comparisons on S&P 500. The CSI 500 backbone ablation is missing.
Deployment costs. The paper runs 5 iterations per trial across 20 independent trials. How many LLM API calls does that require? Token consumption and latency in production are not reported.
Relationship to AlphaGPT. AlphaAgent’s Idea Agent → Factor Agent → Eval Agent loop closely resembles AlphaGPT 2.0’s human-AI collaboration loop. The key difference is the three regularization mechanisms. The ablation study only compares “with regularization vs. without” (hit ratio from 0.16 to 0.29, an 81% improvement), but does not break down the individual contribution of AST deduplication, hypothesis alignment, and complexity control.
Alpha decay is fundamentally information arbitrage. AlphaAgent delays decay by enforcing structural originality, but if AlphaAgent itself becomes widely adopted, its “original” factors become new public knowledge, re-entering the decay cycle. The AST deduplication design can theoretically mitigate this (the factor library keeps updating), but long-term effectiveness requires live trading validation.