上一篇 AlphaGPT 解读留了一个开放问题:当所有人都用 LLM 挖因子,产出的因子能有效多久?AlphaAgent(论文链接,KDD 2025)直接回应了这个问题。它的核心观察是:LLM 生成的因子太依赖已有知识,产出的因子同质化严重,加剧因子拥挤,反而加速了 alpha decay。解决方案是在 LLM 因子生成的过程中加入三重正则化约束,逼迫模型探索结构上新颖、逻辑上自洽、复杂度可控的因子。
Alpha Decay:因子挖掘的核心矛盾
Alpha 因子的生命周期是量化投资里最残酷的现实之一。一个因子被发现后,随着越来越多资金追逐同一个信号,超额收益被逐渐套利掉,因子的预测能力(IC)持续下降,直到失效。这就是 alpha decay。
传统遗传规划(GP)挖出的因子衰减快,因为 GP 倾向于过拟合历史数据,生成过度复杂的表达式。LLM 方法(比如 AlphaGPT、RD-Agent)本来被寄予厚望,但论文指出了一个被忽视的问题:LLM 的预训练知识本身就是"公共知识",基于这些知识生成的因子天然缺乏独创性。大家用同一个 LLM、同一套算子库,产出的因子结构高度相似,等于大家在同一个池子里捞鱼。
AlphaAgent 的论文用实验数据验证了这一点:在 CSI 500 上,Alpha158(一组常用基础因子)的 IC 从 2021 年的 0.022-0.036 衰减到 2024 年接近零。GP 和其他 LLM 方法挖出的因子也呈现类似的衰减趋势。
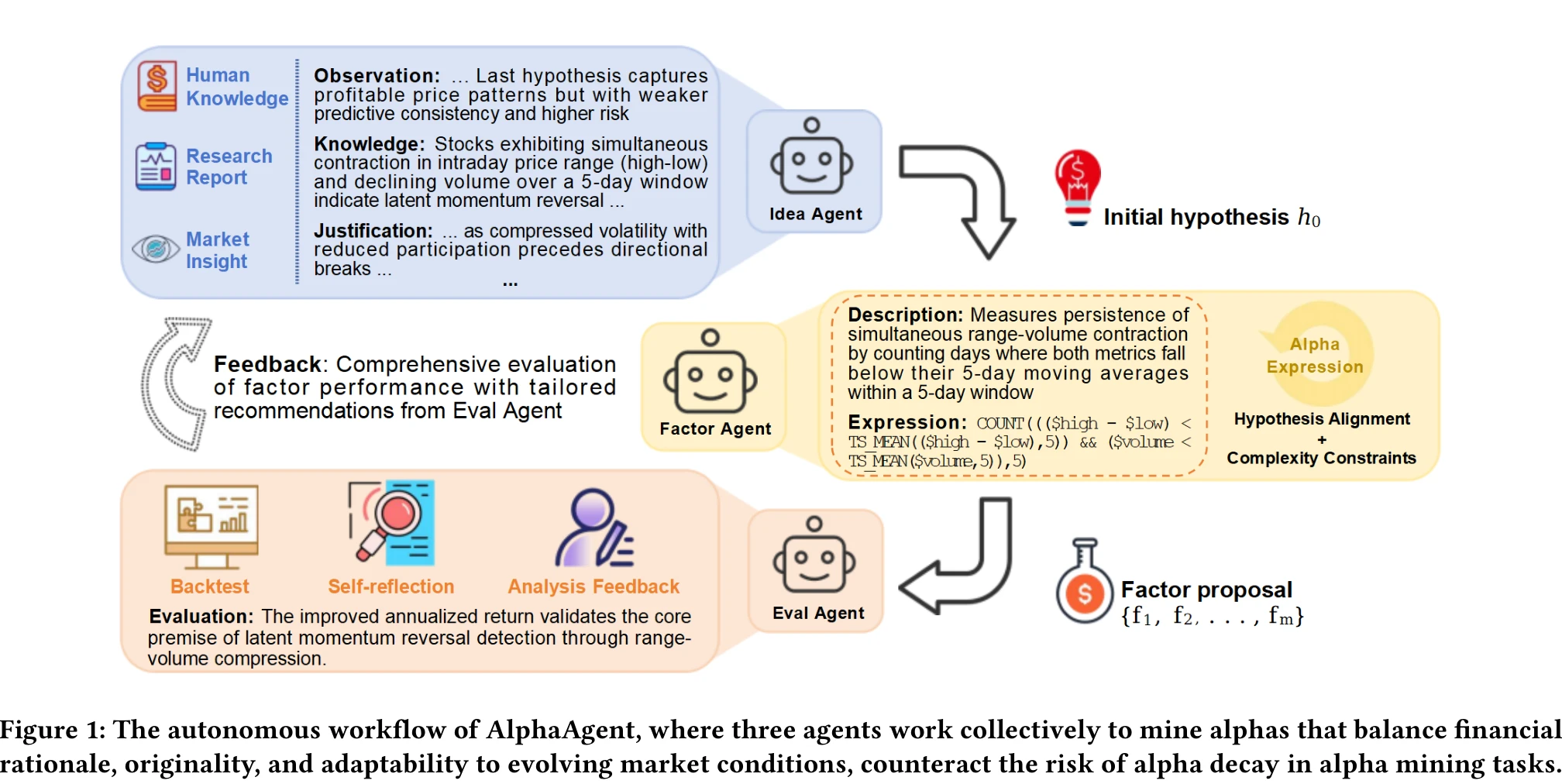
三重正则化:逼 LLM 走出舒适区
AlphaAgent 的核心贡献是一个正则化框架,在因子生成的优化目标里加入三个约束项:
$$ f^* = \arg\max_{f \in \mathcal{F}} \mathcal{L}(f(X), y) - \lambda \cdot R_g(f, h) $$其中 \(\mathcal{L}\) 是因子的预测表现(IC 等),\(R_g\) 是正则化项,由三部分组成:符号长度 SL(控制复杂度)、自由参数数量 PC(防止过拟合)、以及表达式正则项 ER(综合了 AST 去重、假设对齐、特征数量惩罚)。下面分别展开。
AST 去重:结构层面的独创性
每个因子表达式被解析成抽象语法树(AST):叶子节点是原始特征($close、$volume),内部节点是算子(TS_MIN、SMA),边是数据流。
两个因子的相似度定义为它们 AST 之间最大同构子树的节点数:
$$ s(f_i, f_j) = \max_{t_i \subseteq T(f_i), t_j \subseteq T(f_j)} \{|t_i| : t_i \cong t_j\} $$新生成的因子需要和已有的因子库(比如 Alpha101)做比对。如果和已有因子的 AST 重叠度太高,直接拒绝。这逼 LLM 不能只是对已有因子做微小变体,必须在结构上探索新的组合方式。
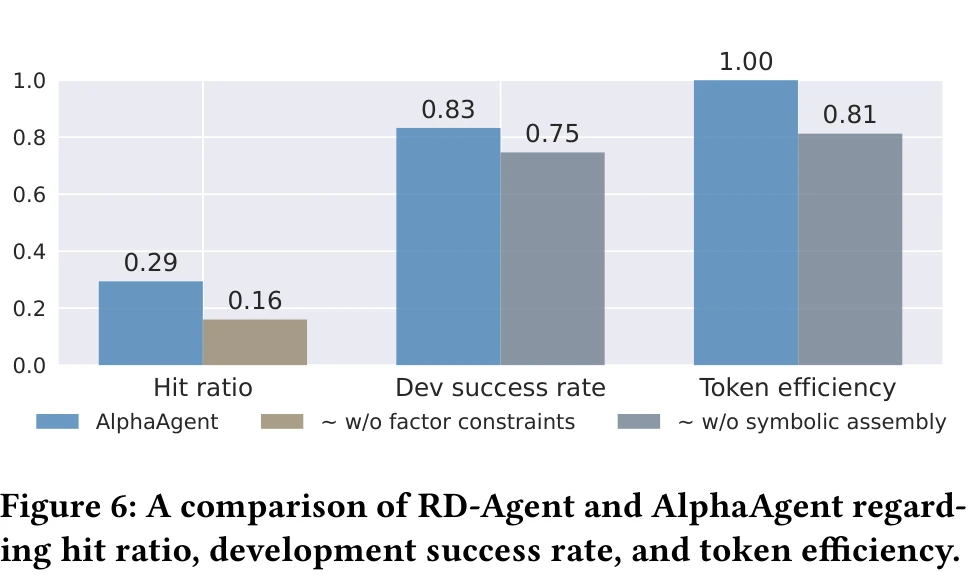
AST 去重是三重正则化中对因子独创性贡献最直接的一项。论文的消融实验显示,去掉全部因子建模约束(AST 去重 + 假设对齐 + 复杂度控制)后,因子的命中率(hit ratio,即产出的因子达到收益阈值的比例)从 0.29 降到 0.16,下降了 45%。
假设-因子对齐:语义层面的自洽
LLM 生成因子分两步:先产生一个市场假设(hypothesis),再把假设翻译成因子表达式。问题是 LLM 经常"说一套做一套",假设说的是"捕捉流动性变化",生成的因子里却没有任何和成交量相关的算子。
AlphaAgent 用一个双重一致性打分函数来检查:
$$ C(h, d, f) = \alpha \cdot c_1(h, d) + (1 - \alpha) \cdot c_2(d, f) $$\(c_1\) 检查因子描述 \(d\) 是否忠实于市场假设 \(h\),\(c_2\) 检查因子表达式 \(f\) 是否忠实于因子描述 \(d\)。两个打分都由 LLM 自身来评判(自我审查)。
这解决了一个 LLM 因子挖掘中很实际的问题:没有这层对齐,LLM 会"编故事",生成的因子和它声称的逻辑完全脱节。回测表现好只是因为过拟合,不是因为因子真的在捕捉假设描述的市场现象。
复杂度控制:防止过度工程
第三个约束直接限制因子表达式的复杂度:
- 符号长度 SL(f):惩罚过深或过宽的 AST
- 自由参数数量 PC(f):惩罚滚动窗口等超参数过多的因子
直觉很简单:一个因子如果嵌套了 8 层算子、用了 5 个不同的窗口参数,即使回测 IC 很高,过拟合的概率也极大。复杂度控制把这些过度工程的因子在生成阶段就过滤掉。
多 Agent 架构
AlphaAgent 用三个 LLM Agent 组成一个闭环:
Idea Agent 负责生成市场假设。它用 chain-of-thought 推理,输出包含四个部分:观察(当前市场状态和上一轮反馈)、知识(金融理论,动量、均值回归、行为金融等)、论证(把观察和知识连起来)、规格(具体的参数建议)。
Factor Agent 把假设翻译成因子表达式。它维护一个不断更新的知识库,记录哪些因子成功了、哪些失败了、失败的原因是什么(假设不对齐?结构太复杂?和已有因子太像?)。生成多个候选因子后,过三重正则化的筛选,只保留通过的。
Eval Agent 对因子做回测评估,从预测能力(IC、RankIC)、收益表现(年化收益、信息比率)、风险控制(最大回撤、稳定性)三个维度打分。评估结果以结构化反馈的形式传回 Idea Agent,驱动下一轮假设的调整。
每轮试验跑 5 个迭代轮次,论文实验共跑了 20 个独立试验。
实验结果
论文在 CSI 500(A 股)和 S&P 500(美股)两个市场做了测试。训练期 2015-2019,验证期 2020,测试期 2021-2025 年初。用 Qlib 做回测框架,LightGBM 做下游预测模型,交易策略是按预测收益排序选前 50 只股票。
对比了一堆基线:LSTM、Transformer、LightGBM、StockMixer、TRA(时序/树模型),AlphaForge(RL+DL)、RD-Agent(LLM,用 GPT-4-turbo),以及 OpenAI o1 和 DeepSeek-R1(深度推理模型)。
核心结果(2021-2024 年测试期):
| 方法 | CSI 500 IC | CSI 500 年化收益 | CSI 500 IR | S&P 500 IC | S&P 500 年化收益 | S&P 500 IR |
|---|---|---|---|---|---|---|
| LSTM | 0.0175 | 4.96% | 0.62 | 0.0028 | -1.51% | -0.17 |
| LightGBM | 0.0120 | -1.18% | -0.16 | 0.0011 | -2.64% | -0.42 |
| AlphaForge | 0.0146 | 3.45% | 0.33 | 0.0026 | 2.45% | 0.34 |
| RD-Agent | 0.0113 | 0.78% | 0.07 | 0.0019 | 1.69% | 0.17 |
| DeepSeek-R1 | 0.0132 | 1.58% | 0.21 | 0.0048 | 2.75% | 0.24 |
| OpenAI o1 | 0.0159 | 0.46% | 0.06 | 0.0028 | 2.29% | 0.20 |
| AlphaAgent | 0.0212 | 11.00% | 1.49 | 0.0056 | 8.74% | 1.05 |
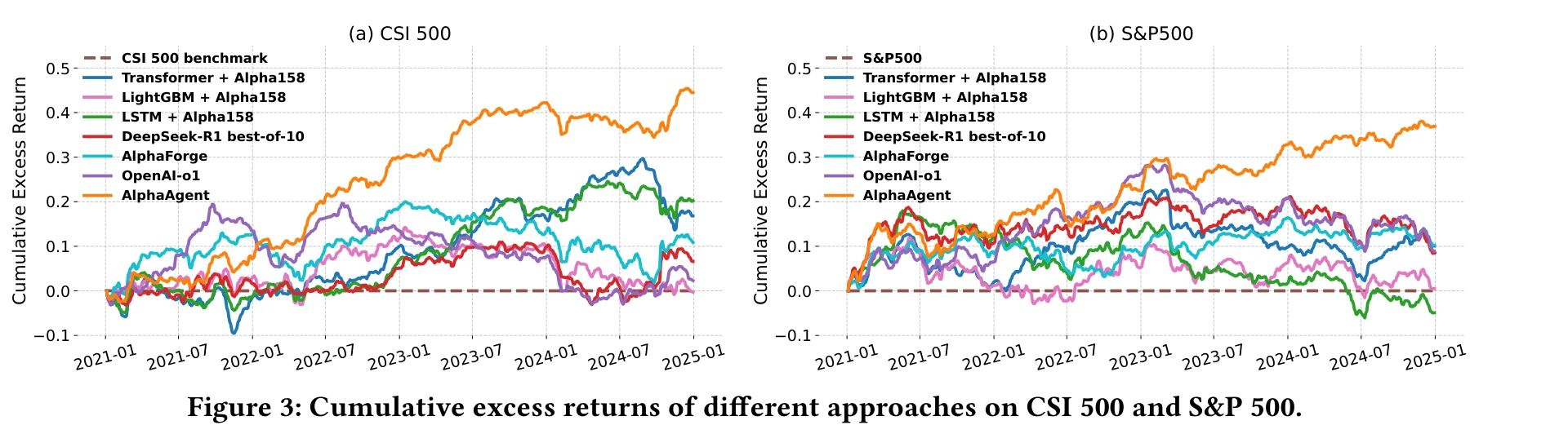
AlphaAgent 在所有指标上都是最优。CSI 500 累计超额收益约 45%,S&P 500 超过 37%。IR(信息比率)1.49 和 1.05 远超其他方法,说明收益不是靠承担大风险换来的。
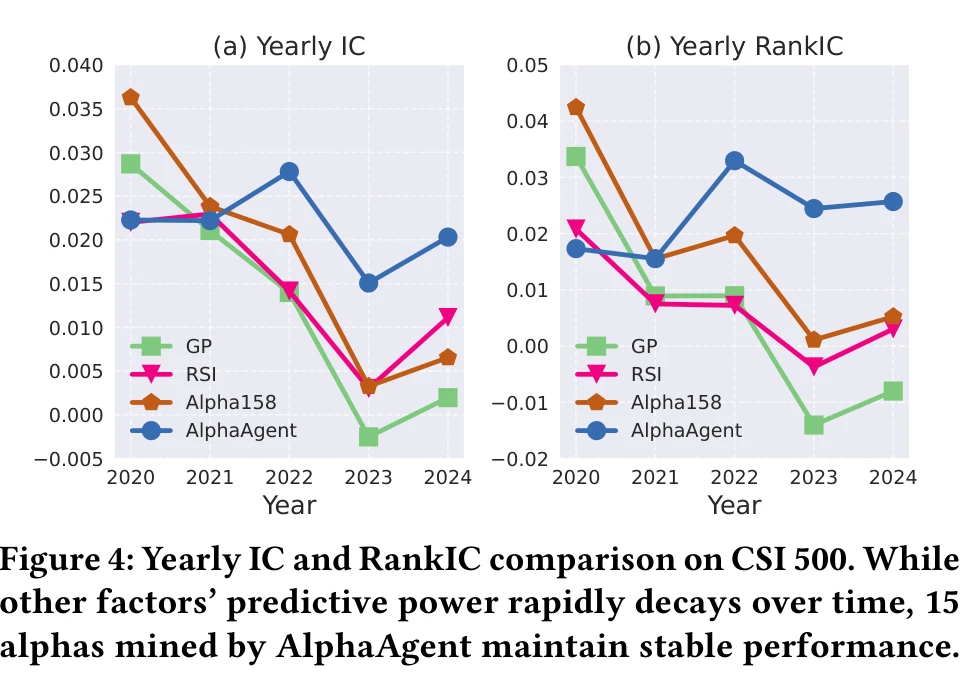
更值得关注的是 alpha decay 的对比。论文画了 2021-2024 每年的 IC 变化:Alpha158 的 IC 逐年衰减到接近零,GP 和 RD-Agent 也在衰减,但 AlphaAgent 挖出的 15 个因子的 IC 在四年里保持在 0.02 左右,没有明显下降。这直接验证了三重正则化在对抗因子衰减上的效果。
LLM 骨干的选择上,论文也做了对比:GPT-3.5-turbo(默认)、Qwen-Plus、DeepSeek-R1 都能跑,DeepSeek-R1 作为骨干时表现最好(S&P 500 年化 9.19%,最大回撤 -6.50%)。所有骨干相比 RD-Agent 的 p 值都小于 0.05,改进是统计显著的。
局限和思考
论文的结果很强,但有几个值得注意的点。
回测 ≠ 实盘。测试期是 2021-2025,但这是回测数据,不是实盘交易。CSI 500 的交易成本只算了 0.05%(买)+ 0.15%(卖),没有考虑冲击成本和滑点。对于选 50 只股票的策略来说,这个假设偏乐观。
GPT-3.5-turbo 作为默认骨干。论文大部分实验用的是 GPT-3.5-turbo,这在 2025 年已经不是最强的模型。用 DeepSeek-R1 做骨干效果更好,但论文只在 S&P 500 上做了骨干对比,CSI 500 上的骨干消融实验缺失。
因子的实际部署问题。论文每轮试验跑 5 个迭代、20 个独立试验,一共要调用多少次 LLM API?token 消耗和延迟在实际生产中是不是可接受的?论文没有给出具体的计算成本数据。
和 AlphaGPT 的关系。AlphaAgent 的 Idea Agent → Factor Agent → Eval Agent 闭环和 AlphaGPT 2.0 的人机协作闭环在结构上很像,核心区别在于三重正则化的加入。论文的消融实验只对比了"有正则化 vs 无正则化"(命中率从 0.16 到 0.29,提升 81%),但 AST 去重、假设对齐、复杂度控制各自贡献了多少,没有细粒度的拆分。
Alpha decay 的本质是信息套利。AlphaAgent 通过强制因子结构的独创性来延缓衰减,但如果 AlphaAgent 本身被广泛使用,它产出的"独创"因子也会变成新的公共知识,重新进入衰减周期。论文的 AST 去重设计理论上可以缓解这个问题(因子库会不断更新),但长期效果需要实盘验证。